Subsections of ☁️CSP Related
72602
Scope
This section is the single source of truth for 72602 cluster operations.
Topology
- Public ECS:
47.110.67.161(2C4G, Aliyun Hongkong) - Active ingress domain:
72602.space; legacy.72602.onlineroutes are retired - ArgoCD host:
argocd.72602.space - k3s node:
72602-minipc(192.168.0.25, MiniPC N100 28G+1TB NVMe) - SSH reverse tunnel:
:10021(main),:10022(backup, also carries80/443) - Ingress NodePort:
32080(HTTP),32443(HTTPS) - Ingress class:
nginx - Ingress namespace:
basic-components - cert-manager issuer:
lets-encrypt - Storage class:
local-path(default, RWO) - OS: Ubuntu 26.04 LTS (minipc)
- k3s version: v1.34.6+k3s1 (installed via install.sh)
Traffic Path
Internet -> ECS(sshd reverse tunnel) -> minipc:k3s ingress-nginx
ECS Port Forwarding
All traffic reaches ECS via SSH reverse tunnel established from minipc. ECS side ports:
10021 -> minipc:22(72602 main SSH)10022 -> minipc:22(72602 backup SSH, also carries80→32080,443→32443)80 -> minipc:32080(HTTP via SSH reverse tunnel on 10022)443 -> minipc:32443(HTTPS via SSH reverse tunnel on 10022)
DNS Setup
Active service records use 72602.space and point to 47.110.67.161:
| Host | Type | Value | Service |
|---|---|---|---|
argocd.72602.space | A | 47.110.67.161 | ArgoCD UI |
ops.docs.72602.space | A | 47.110.67.161 | Hugo Docs |
sub2api.72602.space | A | 47.110.67.161 | AI API proxy |
port.72602.space | A | 47.110.67.161 | Homepage dashboard |
n8n.72602.space | A | 47.110.67.161 | N8N workflow |
webhook.n8n.72602.space | A | 47.110.67.161 | N8N webhook receiver |
ops.agent.72602.space | A | 47.110.67.161 | OpenCode operations agent |
uptime.72602.space | A | 47.110.67.161 | Uptime Kuma |
clash.72602.space | A | 47.110.67.161 | Clash/mihomo panel |
api.minio.72602.space | A | 47.110.67.161 | MinIO S3 API |
console.minio.72602.space | A | 47.110.67.161 | MinIO Console |
txt2img.agent.72602.online is retired. Its DNS record, certificate, TLS Secret, and unreferenced ai data claims have been removed.
DNS is managed via Cloudflare / Aliyun DNS (add A record → ECS IP).
Deployed ArgoCD Apps
| App | Namespace | Type | Source | Ingress |
|---|---|---|---|---|
| argocd | argocd | Helm (arco-cd) | argo-cd 9.5.4 | argocd.72602.space |
| cert-manager | basic-components | Helm (Jetstack) | cert-manager 1.20.2 | internal |
| ingress-nginx | basic-components | Helm | ingress-nginx 4.15.1 | shared ingress controller |
| ops-docs | application | manifests (Git) | docs.git/main | ops.docs.72602.space |
| homepage | monitor | manifests (Git) | docs.git/main | port.72602.space |
| uptime-kuma | monitor | manifests (Git) | docs.git/main | uptime.72602.space |
| sub2api | application | Helm (ghcr) | sub2api 0.1.1 | sub2api.72602.space |
| postgresql | database | Helm (Bitnami) | postgresql 18.1.8 | internal |
| redis-shared | storage | Helm (Bitnami) | redis 18.16.0 | internal |
| minio | storage | Helm | minio 16.0.10 | console.minio.72602.space, api.minio.72602.space |
| n8n | n8n | Helm (community) | n8n 1.16.36 | n8n.72602.space, webhook.n8n.72602.space |
Non-ArgoCD (手动部署)
| Deployment | Namespace | Image | Ingress |
|---|---|---|---|
| ops-agent | application | ay-dev/ops-agent:0.2.2 | ops.agent.72602.space |
Network Proxy
Egress Proxy Architecture
k8s Pod (10.42.x.x) --HTTP_PROXY--> 192.168.0.25:17890 (socat) --forward--> 127.0.0.1:7890 (mihomo/clash) --tunnel--> upstream proxies- mihomo (clash): listens on
127.0.0.1:7890(HTTP),127.0.0.1:7891(SOCKS5)- Config:
/home/aaron/clashctl/resources/runtime.yaml - Key setting:
allow-lan: false(只监听 localhost)
- Config:
- socat bridge:
0.0.0.0:17890→127.0.0.1:7890(桥接使 k8s Pod 可达)- 进程:
socat -d -d TCP-LISTEN:17890,fork,reuseaddr,bind=0.0.0.0 TCP:127.0.0.1:7890
- 进程:
- k8s Service:
argocd-egress-proxy.argocd.svc.cluster.local(ClusterIP:10.43.42.223:17890) → Host192.168.0.25:17890 - App proxy env: 应统一使用
http://192.168.0.25:17890(不是192.168.0.25:7890,因为 mihomo 仅绑定127.0.0.1)
关键约束
- mihomo
allow-lan: false意味着 不能 直接用192.168.0.25:7890作为代理地址 - 必须通过 socat 桥接 (
192.168.0.25:17890) 或argocd-egress-proxyService 访问 - GitHub acceleration:
ghfast.topURL rewrite +NO_PROXYbypass - Image mirror:
m.daocloud.io/docker.io,m.daocloud.io/ghcr.io
Known Incident Pattern
Symptom: HTTPS handshake fails for
argocd.72602.online(tls alert internal error).Root cause: ECS Docker/derper occupies public
443, traffic never reaches k3s ingress.Fix baseline: derper must expose
8443:443, keep public443for ingress NodePort32443.Symptom: n8n 所有 workflow 报
connect ECONNREFUSED 192.168.0.25:7890。Root cause: HTTP_PROXY 指向
192.168.0.25:7890,但 mihomo 只监听127.0.0.1:7890(allow-lan: false)。Pod 无法直连 mihomo 的 LAN IP。Fix baseline: HTTP_PROXY/HTTPS_PROXY 必须使用 socat 桥接端口
192.168.0.25:17890(或 k8s Service10.43.19.4:17890),该端口由 socat 转发至127.0.0.1:7890。
Host-Level Services
| Service | Port | Bind | Description |
|---|---|---|---|
| mihomo (clash) HTTP proxy | 7890 | 127.0.0.1 | Egress proxy, allow-lan: false |
| mihomo (clash) SOCKS5 | 7891 | 127.0.0.1 | SOCKS5 proxy |
| mihomo external controller | 9090 | 0.0.0.0 | Clash API/UI, exposed via clash.72602.space |
| socat bridge | 17890 | 0.0.0.0 | Forwards to 127.0.0.1:7890, k8s pod accessible |
| autossh tunnel (main) | 10021→ECS | - | Reverse tunnel to ECS |
| autossh tunnel (backup) | 10022→ECS | - | Reverse tunnel + HTTP/HTTPS forwarding |
| k3s ingress HTTP | 32080 | 0.0.0.0 | NodePort for ingress HTTP |
| k3s ingress HTTPS | 32443 | 0.0.0.0 | NodePort for ingress HTTPS |
Notes
- Keep
derperaway from public443(use8443). - Keep app ingress aligned with ArgoCD ingress pattern:
ingressClassName: nginxcert-manager.io/cluster-issuer: lets-encrypt- TLS secret per host.
argocd-egress-proxy由ops-docsArgoCD Application 管理,并为 repo-server 提供 Git/Helm 出站代理。- mihomo
allow-lan: false意味着 Pod 代理地址必须是 socat 桥接端口17890,不能用7890。 - SSH 隧道依赖
loginctl enable-linger保持用户级 systemd 服务运行。
Recent Operations
2026-07-16: reset csst and update N8N webhook host
- Deleted and recreated the
csstnamespace. Only the namespace default ServiceAccount andkube-root-ca.crtConfigMap remain. - Changed N8N
WEBHOOK_URL, webhook worker URL, Ingress rule, and TLS DNS name fromwebhook.72602.onlinetowebhook.n8n.72602.online. - Synced ArgoCD application
argocd/n8n; main, webhook, MCP webhook, and worker rollouts completed. - cert-manager completed HTTP-01 validation and issued the updated certificate.
2026-07-16: migrate OpenCode web to k3s
- Replaced the host systemd process and static EndpointSlice with the
application/ops-agentworkload. - The Pod mounts
/home/aaron/Ops/docsat/workspace, loads the project.opencode/opencode.json, and persists sessions in theopencode-dataPVC. - Image
ay-dev/ops-agent:0.2.2uses glibc and contains OpenCode 1.18.2, kubectl 1.34.6, Argo CD CLI 3.3.8, VibeGuard, DCP, and Goal Mode. - OpenCode native Basic Auth protects both Ingress and cluster-internal access. Anonymous HTTPS returns
401; authenticated HTTPS returns200. - An Nginx sidecar publishes the
Ops Agentbrowser title and proxies Terminal WebSocket and event streams.
2026-07-16: remove Langfuse and refresh Homepage
- Permanently removed the seven unused Langfuse PVCs (56 GiB) and six residual Secrets from
monitor. - Removed Langfuse and pgAdmin from Homepage and added the OpenCode operations agent.
- Restored the ArgoCD Homepage widget by binding the
readonlyAPI account torole:readonly.
2026-07-17: align Ops resource names
- Renamed the Hugo workload and its Service, ConfigMap, build Job, and Ingress resources to
ops-docs; retainedhugo-docs-pvcto preserve generated content. - Renamed the OpenCode-based workload, Service, Ingress, proxy ConfigMap, manifest directory, and Dockerfile to
ops-agent; retained existingopencode-*PVC and Secrets to preserve sessions and credentials. - Replaced the manual
local-proxy-bridgewith the GitOps-managedargocd-egress-proxy; ArgoCD repo-server uses its cluster Service while applications can continue using host port17890.
Default Verification Commands
# 公网入口
curl -vI http://argocd.72602.space
curl -vkI https://argocd.72602.space
# k8s 资源
kubectl get ingress -A -o wide
kubectl get svc -A -o wide
kubectl get pods -A -o wide
kubectl get certificate,certificaterequest,order,challenge -A
# 主机端口
sudo ss -lntp | grep -E ':80|:443|:8443|:32080|:32443|:7890|:17890|:9090'
# ECS 转发
sudo iptables -t nat -L PREROUTING -n -v --line-numbers
sudo iptables -t nat -L DOCKER -n -v --line-numbers
# Egress proxy 完整性
curl -s --connect-timeout 3 -x http://127.0.0.1:17890 http://httpbin.org/ip
kubectl exec -n n8n deploy/n8n -- env | grep -E 'HTTP_PROXY|HTTPS_PROXY'
# SSH 隧道
journalctl --user -u reverse-tunnel-ecs-10021.service --since "1 hour ago" --no-pager
journalctl --user -u reverse-tunnel-ecs-10022.service --since "1 hour ago" --no-pagerSubsections of 72602
ECS Security Group
安全组 IP 自动更新
背景
72602-minipc 的 ISP 不定期更换公网 IP,而阿里云 ECS (ecs-99) 安全组限制了 SSH 端口只能从特定 IP 访问。
当公网 IP 变化时:
- SSH 反向隧道断开
- 无法通过
ssh aaron@47.110.67.161 -p 10022访问 - 无法直接
ssh root@47.110.67.161
解决方案
定时检测公网 IP,变化时自动更新阿里云安全组规则。
所有阿里云安全组和 AliDNS 操作统一从 72602-minipc 执行。
工作原理
每 5 分钟 ──> 获取公网 IP (ifconfig.me → ip.sb → icanhazip.com)
│
├── 全部失败 ──> 钉钉告警,退出
│
└── 获取成功 ──> 与上次对比
├── 未变化 ──> 退出
└── 已变化 ──> 更新安全组规则 → 钉钉通知受影响的端口
| 端口 | 用途 |
|---|---|
| 22 | ECS SSH 直接连接、反向隧道 |
| 10021 | 预留 |
| 10022 | SSH 反向隧道(72602-minipc 入口) |
文件位置
| 文件 | 说明 |
|---|---|
/home/aaron/bin/update-sg-ip.sh | 主脚本 |
/home/aaron/.aliyun-keys | 阿里云 AccessKey(chmod 600) |
/etc/systemd/system/update-sg-ip.service | systemd 服务 |
/etc/systemd/system/update-sg-ip.timer | systemd 定时器(每 5 分钟,开机 30 秒后首次触发) |
/tmp/last_public_ip | 上次公网 IP 缓存 |
可恢复备份
脱敏后的可恢复备份位于私有仓库 /home/aaron/Ops/ops-private,对应提交 8abb81d,包含:
scripts/update-sg-ip.sh- systemd service、timer 和
env.example runbooks/72602/security-group-updater.md.gitignore
该提交未包含 AccessKey、钉钉 token 或真实安全组 ID。备份操作未修改现网脚本、systemd units 或 timer。
AliDNS 环境
- 官方 AliDNS SDK 使用独立虚拟环境
/home/aaron/.local/venvs/alidns。 - SDK 或依赖需要下载时,使用 HTTP 代理
http://192.168.0.25:17890。 - 当前凭证具备
72602.online区域的 AliDNS 记录管理能力,也具备 ECS 安全组变更能力。 - DNS 变更前应限定目标区域和记录,并在变更后分别执行权威 DNS 与公共 DNS 验证。
常用命令
# 查看定时器状态
systemctl status update-sg-ip.timer
# 手动触发一次更新
sudo systemctl start update-sg-ip.service
# 查看执行日志
journalctl -u update-sg-ip.service -f
# 查看脚本输出
cat /tmp/update-sg-ip.log
# 手动运行脚本
~/bin/update-sg-ip.sh钉钉通知
脚本支持钉钉机器人通知。需要设置 DING_TOKEN 环境变量或修改脚本中的 DING_TOKEN 变量:
# 在 ~/.aliyun-keys 中添加:
DING_TOKEN=你的钉钉机器人access_token凭证安全
阿里云 AccessKey 存储在 /home/aaron/.aliyun-keys,权限 600。
当前同一 AccessKey 同时具备 ECS 安全组和 AliDNS 变更权限;后续应拆分为两个最小权限 RAM 身份。
/home/aaron/bin/update-sg-ip.sh 当前权限为 0775,仍可由组写入;应收紧为 0755。此项为待执行的加固建议,并非已完成状态。
定期轮换 AccessKey。AccessKey 获取:阿里云控制台 → 头像 → AccessKey 管理。
SSH Tunnel
72602 隧道统一采用双入口反向隧道:
- 主入口:
10021 - 备入口:
10022 - 目标 ECS:
47.110.67.161 (ecs-99)
快速连接命令:
ssh -p 10021 aaron@47.110.67.161
ssh -p 10022 aaron@47.110.67.161上线顺序建议:
- 先在 72602-minipc 创建并启动
10022(备入口) - 验证 ECS 已监听
10022 - 再创建并启动
10021(主入口) - 最后做外网双端口连通性验证
完整步骤、故障恢复与运维命令见子页面。
Subsections of SSH Tunnel
72602-minipc → ecs-99
SSH 反向隧道:72602-minipc → ecs-99(双入口)
本文档是 72602-minipc 的新标准方案,目标是避免单端口掉线导致完全失联。
- 主入口:
10021 - 备入口:
10022 - 两个端口由两个独立 service 维护
一、架构
外网任意机器 ecs-99 (47.110.67.161) 72602-minipc (192.168.0.25)
ssh -p 10021 aaron@47.110.67.161 -> 0.0.0.0:10021 (sshd) --SSH reverse--> localhost:22
ssh -p 10022 aaron@47.110.67.161 -> 0.0.0.0:10022 (sshd) --SSH reverse--> localhost:22说明:反向隧道必须由 72602-minipc 主动发起。ECS 上看到端口监听,才表示隧道在线。
二、上线前检查
2.1 在 72602-minipc 检查基础条件
# 1) 本机 SSH 服务
sudo systemctl is-active ssh
# 2) autossh 是否安装
autossh -V
# 3) 本机到 ECS 网络与认证
ssh -o ConnectTimeout=5 root@47.110.67.161 hostname
# 期望输出: ecs-992.2 在 ECS 检查前置配置
/etc/ssh/sshd_config 至少包含:
GatewayPorts clientspecified重载:
sudo systemctl reload sshd安全组放行:10021/tcp、10022/tcp(授权范围按你自己的安全策略)。
同时确认 ECS 本机防火墙(UFW)放行这两个端口:
sudo ufw status numbered
# 至少应包含 10021/tcp 和 10022/tcp 的 ALLOW 规则三、创建双 service(72602-minipc 上执行)
下面步骤全部在 72602-minipc 上执行。
3.1 统一 SSH 客户端配置(可选但推荐)
编辑 ~/.ssh/config:
Host ecs-99
HostName 47.110.67.161
User root
ServerAliveInterval 60
ServerAliveCountMax 3
ExitOnForwardFailure yes
TCPKeepAlive yes
ConnectTimeout 103.2 创建 systemd 用户服务目录
mkdir -p ~/.config/systemd/user3.3 新建 service(10021 主)
文件:~/.config/systemd/user/reverse-tunnel-ecs-10021.service
[Unit]
Description=Reverse SSH tunnel to ecs-99 (port 10021 -> local SSH)
After=network-online.target
Wants=network-online.target
[Service]
Type=simple
Environment="AUTOSSH_GATETIME=0"
Environment="AUTOSSH_POLL=60"
Environment="AUTOSSH_FIRST_POLL=30"
ExecStart=/usr/bin/autossh -M 0 -N -R 0.0.0.0:10021:localhost:22 ecs-99
Restart=always
RestartSec=10
StandardOutput=journal
StandardError=journal
[Install]
WantedBy=default.target3.4 新建 service(10022 备,含 HTTP/HTTPS)
文件:~/.config/systemd/user/reverse-tunnel-ecs-10022.service
[Unit]
Description=Reverse SSH tunnel to ecs-99 (port 10022 -> local SSH)
After=network-online.target
Wants=network-online.target
[Service]
Type=simple
Environment="AUTOSSH_GATETIME=0"
Environment="AUTOSSH_POLL=60"
Environment="AUTOSSH_FIRST_POLL=30"
ExecStart=/usr/bin/autossh -M 0 -N \
-R 0.0.0.0:10022:localhost:22 \
-R 0.0.0.0:80:localhost:32080 \
-R 0.0.0.0:443:localhost:32443 \
ecs-99
Restart=always
RestartSec=10
StandardOutput=journal
StandardError=journal
[Install]
WantedBy=default.target说明:10022 的 service 额外承载 72602-minipc 的 HTTP(
32080→80)和 HTTPS(32443→443)服务。如果不需要公网 Web 服务,可只保留 SSH 转发。
3.5 启用并启动
export XDG_RUNTIME_DIR=/run/user/$(id -u)
systemctl --user daemon-reload
systemctl --user enable --now reverse-tunnel-ecs-10021.service
systemctl --user enable --now reverse-tunnel-ecs-10022.service
systemctl --user status reverse-tunnel-ecs-10021.service --no-pager
systemctl --user status reverse-tunnel-ecs-10022.service --no-pager3.6 防登出失效(强烈建议)
sudo loginctl enable-linger aaron
loginctl show-user aaron | grep Linger
# 期望: Linger=yes四、连通性验证
4.1 在 ECS 上看监听
ssh root@47.110.67.161 "ss -tlnp | grep -E '10021|10022'"期望看到:
0.0.0.0:100210.0.0.0:10022
4.2 在外网验证
nc -zv 47.110.67.161 10021
nc -zv 47.110.67.161 10022
ssh -p 10021 aaron@47.110.67.161
ssh -p 10022 aaron@47.110.67.161若 10021/10022 外网超时,但 ECS 上已监听,优先检查:
- 云安全组来源网段是否覆盖当前出口 IP
- ECS UFW 是否放行对应端口
五、故障恢复(按顺序)
场景 A:ECS 本机 ssh localhost -p 10022 失败
这说明 ECS 上没有监听 10022,问题几乎总在源机器(72602-minipc)侧。
在 72602-minipc 执行:
export XDG_RUNTIME_DIR=/run/user/$(id -u)
# 1) 看 service
systemctl --user status reverse-tunnel-ecs-10021.service --no-pager
systemctl --user status reverse-tunnel-ecs-10022.service --no-pager
# 2) 重启 service
systemctl --user restart reverse-tunnel-ecs-10021.service
systemctl --user restart reverse-tunnel-ecs-10022.service
# 3) 看日志
journalctl --user -u reverse-tunnel-ecs-10021.service --since "10 min ago" --no-pager
journalctl --user -u reverse-tunnel-ecs-10022.service --since "10 min ago" --no-pager
# 4) 验证到 ECS 的基础连通
ssh -o ConnectTimeout=5 root@47.110.67.161 echo ok场景 B:外网超时但 ECS 本机可通
问题在安全组或 ECS 防火墙,不在隧道本身。
ssh root@47.110.67.161 "ss -tlnp | grep -E '10021|10022'"
ssh root@47.110.67.161 "iptables -L INPUT -n | grep -E '10021|10022' || true"场景 C:重启后隧道没起来
export XDG_RUNTIME_DIR=/run/user/$(id -u)
systemctl --user is-enabled reverse-tunnel-ecs-10021.service
systemctl --user is-enabled reverse-tunnel-ecs-10022.service
loginctl show-user aaron | grep Linger六、常用运维命令
export XDG_RUNTIME_DIR=/run/user/$(id -u)
# 重载并重启
systemctl --user daemon-reload
systemctl --user restart reverse-tunnel-ecs-10021.service
systemctl --user restart reverse-tunnel-ecs-10022.service
# 停止
systemctl --user stop reverse-tunnel-ecs-10021.service
systemctl --user stop reverse-tunnel-ecs-10022.service
# 日志实时跟踪
journalctl --user -u reverse-tunnel-ecs-10021.service -f
journalctl --user -u reverse-tunnel-ecs-10022.service -f七、和现网监控的关系
ECS 侧巡检仅监控 72602-minipc 的两个公开入口。
当 72602-minipc 双入口上线后,ECS 无需改架构,只要确认:
- 安全组已放行
10021/10022 /etc/tunnel-healthcheck-ports.conf包含10021、10022/etc/tunnel-healthcheck.env企业应用参数可用(DINGTALK_CLIENT_ID/SECRET/AGENT_ID/USER_IDS)
当前线上实现:
- 告警通道为钉钉企业应用 API(非 webhook)
- 告警消息为 Markdown 格式(标题:
🚨 ECS Tunnel Alert) - 连续失败 3 次才发送告警(防抖)
Aliyun
Subsections of Aliyun
OSSutil
download ossutil
first, you need to download ossutil first
OS:
curl https://gosspublic.alicdn.com/ossutil/install.sh | sudo bashcurl -o ossutil-v1.7.19-windows-386.zip https://gosspublic.alicdn.com/ossutil/1.7.19/ossutil-v1.7.19-windows-386.zipconfig ossutil
./ossutil config| Params | Description | Instruction |
|---|---|---|
| endpoint | the Endpoint of the region where the Bucket is located | |
| accessKeyID | OSS AccessKey | get from user info panel |
| accessKeySecret | OSS AccessKeySecret | get from user info panel |
| stsToken | token for sts service | could be empty |
Info
you can also modify /home/<$user>/.ossutilconfig file directly to change the configuration.
list files
ossutil ls oss://<$PATH>download file/dir
you can use cp to download or upload file
ossutil cp -r oss://<$PATH> <$PTHER_PATH>upload file/dir
ossutil cp -r <$SOURCE_PATH> oss://<$PATH>ECS DNS
ZJADC (Aliyun Directed Cloud)
Append content in /etc/resolv.conf
options timeout:2 attempts:3 rotate
nameserver 10.255.9.2
nameserver 10.200.12.5And then you probably need to modify yum.repo.d as well, check link
YQGCY (Aliyun Directed Cloud)
Append content in /etc/resolv.conf
nameserver 172.27.205.79And then restart kube-system.coredns-xxxx
Google DNS
nameserver 8.8.8.8
nameserver 4.4.4.4
nameserver 223.5.5.5
nameserver 223.6.6.6Restart DNS
OS:
vim /etc/NetworkManager/NetworkManager.confvim /etc/NetworkManager/NetworkManager.confsudo systemctl is-active systemd-resolved
sudo resolvectl flush-caches
# or sudo systemd-resolve --flush-cachesadd "dns=none" under '[main]' part
systemctl restart NetworkManagerModify ifcfg-ethX [Optional]
if you cannot get ipv4 address, you can try to modify ifcfg-ethX
vim /etc/sysconfig/network-scripts/ifcfg-ens33set ONBOOT=yes
Huawei
Tencent
Zhejianglab
Scope
ZJLAB operational inventory and network details are private. Public pages contain reusable application guidance only; verify dynamic state against the live cluster before applying a runbook.
Access
ssh zjlab hostname
ssh zjlab 'kubectl get nodes'
ssh zjlab-backup hostnameThe aliases are provisioned from private inventory and use an ECS ProxyJump to loopback-only reverse SSH listeners. Do not publish their resolved endpoints, ports, users, internal topology, or service names.
Detailed inventory and tunnel recovery procedures are maintained in the private ops-private repository with SOPS-encrypted values.
Preflight
ssh zjlab 'kubectl config current-context'
ssh zjlab 'kubectl get nodes'
ssh zjlab 'kubectl get namespace'
ssh zjlab 'kubectl get applications.argoproj.io -A'
ssh zjlab 'kubectl get ingress,certificate -A'Subsections of Zhejianglab
👨💻Schedmd Slurm
The Slurm Workload Manager, formerly known as Simple Linux Utility for Resource Management (SLURM), or simply Slurm, is a free and open-source job scheduler for Linux and Unix-like kernels, used by many of the world’s supercomputers and computer clusters.
It provides three key functions:
- allocating exclusive and/or non-exclusive access to resources (computer nodes) to users for some duration of time so they can perform work,
- providing a framework for starting, executing, and monitoring work, typically a parallel job such as Message Passing Interface (MPI) on a set of allocated nodes, and
- arbitrating contention for resources by managing a queue of pending jobs.
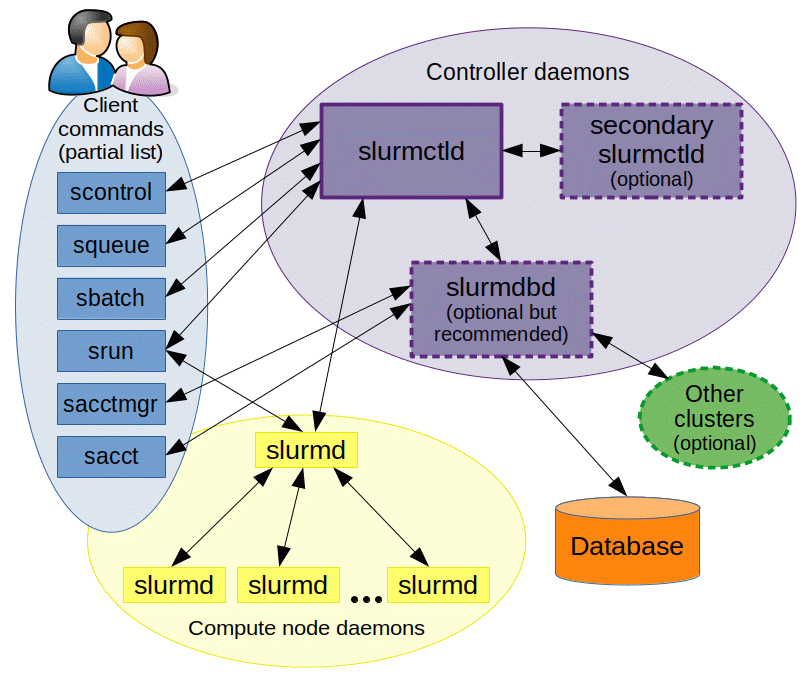
Content
Subsections of 👨💻Schedmd Slurm
Build & Install
Install Slurm from Debian
Install Slurm from Ubuntu
Install Slurm from binary
Install Slurm from helm chart
Install Slurm from K8s Operator
What is SCOW? SCOW is a HPC cluster management system built by PKU. SCOW used four virtual machines to run slurm cluster. It is a good choice for you to learn how to use slurm. You should check https://pkuhpc.github.io/OpenSCOW/docs/hpccluster, it works well.
Subsections of Build & Install
Install On Debian
Cluster Setting
- 1 Manager
- 1 Login Node
- 2 Compute nodes
| hostname | IP | role | quota |
|---|---|---|---|
| manage01 (slurmctld, slurmdbd) | 192.168.56.115 | manager | 2C4G |
| login01 (login) | 192.168.56.116 | login | 2C4G |
| compute01 (slurmd) | 192.168.56.117 | compute | 2C4G |
| compute02 (slurmd) | 192.168.56.118 | compute | 2C4G |
Software Version:
| software | version |
|---|---|
| os | Debian 12 bookworm |
| slurm | 24.05.2 |
Important
when you see (All Nodes), you need to run the following command on all nodes
when you see (Manager Node), you only need to run the following command on manager node
when you see (Login Node), you only need to run the following command on login node
Prepare Steps (All Nodes)
- Modify the
/etc/apt/sources.listfile Using tuna mirror
cat > /etc/apt/sources.list << EOF
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm main contrib non-free non-free-firmware
deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm main contrib non-free non-free-firmware
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm-updates main contrib non-free non-free-firmware
deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm-updates main contrib non-free non-free-firmware
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm-backports main contrib non-free non-free-firmware
deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm-backports main contrib non-free non-free-firmware
deb https://mirrors.tuna.tsinghua.edu.cn/debian-security/ bookworm-security main contrib non-free non-free-firmware
deb-src https://mirrors.tuna.tsinghua.edu.cn/debian-security/ bookworm-security main contrib non-free non-free-firmware
EOF- Update apt cache
apt clean all && apt update- Set hostname on each node
Node:
hostnamectl set-hostname manage01
hostnamectl set-hostname login01
hostnamectl set-hostname compute01
hostnamectl set-hostname compute02- Set hosts file
cat >> /etc/hosts << EOF
192.168.56.115 manage01
192.168.56.116 login01
192.168.56.117 compute01
192.168.56.118 compute02
EOF- Disable firewall
systemctl stop nftables && systemctl disable nftables- Install packages
ntpdate
apt-get -y install ntpdate- Sync server time
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
echo 'Asia/Shanghai' >/etc/timezone
ntpdate time.windows.com- Add cron job to sync time
crontab -e
*/5 * * * * /usr/sbin/ntpdate time.windows.com- Create ssh key pair on each node
ssh-keygen -t rsa -b 4096 -C $HOSTNAME- Test ssh login other nodes without password
Node:
ssh-copy-id -i ~/.ssh/id_rsa.pub root@login01
ssh-copy-id -i ~/.ssh/id_rsa.pub root@compute01
ssh-copy-id -i ~/.ssh/id_rsa.pub root@compute02
ssh-copy-id -i ~/.ssh/id_rsa.pub root@manage01
ssh-copy-id -i ~/.ssh/id_rsa.pub root@compute01
ssh-copy-id -i ~/.ssh/id_rsa.pub root@compute02Install Components
- Install NFS server
(Manager Node)
there are many ways to install NFS server
- using
yum install -y nfs-utils, check https://pkuhpc.github.io/SCOW/docs/hpccluster/nfs - using
apt install -y nfs-kernel-server, check https://www.linuxtechi.com/how-to-install-nfs-server-on-debian/ - or you can directly mount other shared storage.
create shared folder
mkdir /data
chmod 755 /datamodify vim /etc/exports
/data *(rw,sync,insecure,no_subtree_check,no_root_squash)start nfs server
systemctl start rpcbind
systemctl start nfs-server
systemctl enable rpcbind
systemctl enable nfs-servercheck nfs server
showmount -e localhost
# Output
Export list for localhost:
/data *
- Install munge service
- add user munge
(All Nodes)
groupadd -g 1108 munge
useradd -m -c "Munge Uid 'N' Gid Emporium" -d /var/lib/munge -u 1108 -g munge -s /sbin/nologin munge- Install
rng-tools-debian(Manager Nodes)
apt-get install -y rng-tools-debian# modify service script
vim /usr/lib/systemd/system/rngd.service[Service]
ExecStart=/usr/sbin/rngd -f -r /dev/urandomsystemctl daemon-reload
systemctl start rngd
systemctl enable rngdapt-get install -y libmunge-dev libmunge2 munge- generate secret key
(Manager Nodes)
dd if=/dev/urandom bs=1 count=1024 > /etc/munge/munge.key- copy
munge.keyfrom manager node to the rest node(All Nodes)
scp -p /etc/munge/munge.key root@login01:/etc/munge/
scp -p /etc/munge/munge.key root@compute01:/etc/munge/
scp -p /etc/munge/munge.key root@compute02:/etc/munge/- grant privilege on munge.key
(All Nodes)
chown munge: /etc/munge/munge.key
chmod 400 /etc/munge/munge.key
systemctl start munge
systemctl enable mungeUsing systemctl status munge to check if the service is running
- test munge
munge -n | ssh compute01 unmunge
- Install Mariadb
(Manager Nodes)
apt-get install -y mariadb-server- create database and user
systemctl start mariadb
systemctl enable mariadb
ROOT_PASS=$(tr -dc A-Za-z0-9 </dev/urandom | head -c 16)
mysql -e "CREATE USER root IDENTIFIED BY '${ROOT_PASS}'"
mysql -uroot -p$ROOT_PASS -e 'create database slurm_acct_db'- create user
slurm,and grant all privileges on databaseslurm_acct_db
mysql -uroot -p$ROOT_PASScreate user slurm;
grant all on slurm_acct_db.* TO 'slurm'@'localhost' identified by '123456' with grant option;
flush privileges;- create Slurm user
groupadd -g 1109 slurm
useradd -m -c "Slurm manager" -d /var/lib/slurm -u 1109 -g slurm -s /bin/bash slurmInstall Slurm (All Nodes)
- Install basic Debian package build requirements:
apt-get install -y build-essential fakeroot devscripts equivs- Unpack the distributed tarball:
wget https://download.schedmd.com/slurm/slurm-24.05.2.tar.bz2 -O slurm-24.05.2.tar.bz2 &&
tar -xaf slurm*tar.bz2- cd to the directory containing the Slurm source:
cd slurm-24.05.2 && mkdir -p /etc/slurm && ./configure - compile slurm
make installmodify configuration files
(Manager Nodes)- modify
/etc/slurm/slurm.confRefer to slurm.conf
cp /root/slurm-24.05.2/etc/slurm.conf.example /etc/slurm/slurm.conf vim /etc/slurm/slurm.conffocus on these options:
SlurmctldHost=manage AccountingStorageEnforce=associations,limits,qos AccountingStorageHost=manage AccountingStoragePass=/var/run/munge/munge.socket.2 AccountingStoragePort=6819 AccountingStorageType=accounting_storage/slurmdbd JobCompHost=localhost JobCompLoc=slurm_acct_db JobCompPass=123456 JobCompPort=3306 JobCompType=jobcomp/mysql JobCompUser=slurm JobContainerType=job_container/none JobAcctGatherType=jobacct_gather/linux- modify
/etc/slurm/slurmdbd.confRefer to slurmdbd.conf
cp /root/slurm-24.05.2/etc/slurmdbd.conf.example /etc/slurm/slurmdbd.conf vim /etc/slurm/slurmdbd.conf- modify
/etc/slurm/cgroup.conf
cp /root/slurm-24.05.2/etc/cgroup.conf.example /etc/slurm/cgroup.conf- send configuration files to other nodes
scp -r /etc/slurm/*.conf root@login01:/etc/slurm/ scp -r /etc/slurm/*.conf root@compute01:/etc/slurm/ scp -r /etc/slurm/*.conf root@compute02:/etc/slurm/- modify
grant privilege on some directories
(All Nodes)
mkdir /var/spool/slurmd
chown slurm: /var/spool/slurmd
mkdir /var/log/slurm
chown slurm: /var/log/slurm
mkdir /var/spool/slurmctld
chown slurm: /var/spool/slurmctld
chown slurm: /etc/slurm/slurmdbd.conf
chmod 600 /etc/slurm/slurmdbd.conf- start slurm services on each node
Node:
systemctl start slurmdbd
systemctl enable slurmdbd
systemctl start slurmctld
systemctl enable slurmctld
systemctl start slurmd
systemctl enable slurmd
systemctl start slurmd
systemctl enable slurmd
systemctl start slurmd
systemctl enable slurmd
systemctl start slurmd
systemctl enable slurmdTest Your Slurm Cluster (Login Node)
- check cluster configuration
scontrol show config- check cluster status
sinfo
scontrol show partition
scontrol show node- submit job
srun -N2 hostname
scontrol show jobs- check job status
check job status
squeue -aInstall On Ubuntu
Cluster Setting
- 1 Manager
- 1 Login Node
- 2 Compute nodes
| hostname | IP | role | quota |
|---|---|---|---|
| manage01 (slurmctld, slurmdbd) | 192.168.56.115 | manager | 2C4G |
| login01 (login) | 192.168.56.116 | login | 2C4G |
| compute01 (slurmd) | 192.168.56.117 | compute | 2C4G |
| compute02 (slurmd) | 192.168.56.118 | compute | 2C4G |
Software Version:
| software | version |
|---|---|
| os | Ubuntu 22.04 |
| slurm | 24.05.2 |
Important
when you see (All Nodes), you need to run the following command on all nodes
when you see (Manager Node), you only need to run the following command on manager node
when you see (Login Node), you only need to run the following command on login node
Prepare Steps (All Nodes)
- Modify the
/etc/apt/sources.listfile Using tuna mirror
cat > /etc/apt/sources.list << EOF
EOF- Update apt cache
apt clean all && apt update- Set hosts file
cat >> /etc/hosts << EOF
10.119.2.36 juice-036
10.119.2.37 juice-037
10.119.2.38 juice-038
EOF- Install packages
ntpdate
apt-get -y install ntpdate- Sync server time
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
echo 'Asia/Shanghai' >/etc/timezone
ntpdate ntp.aliyun.com- Add cron job to sync time
crontab -e
*/5 * * * * /usr/sbin/ntpdate ntp.aliyun.com- Create ssh key pair on each node
ssh-keygen -t rsa -b 4096 -C $HOSTNAME- Test ssh login other nodes without password
Node:
ssh-copy-id -i ~/.ssh/id_rsa.pub root@juice-036
ssh-copy-id -i ~/.ssh/id_rsa.pub root@juice-037
ssh-copy-id -i ~/.ssh/id_rsa.pub root@juice-038Install Components
- Install NFS server
(Manager Node)
there are many ways to install NFS server
- using
apt install -y nfs-kernel-server, check https://www.linuxtechi.com/how-to-install-nfs-server-on-debian/
create shared folder
mkdir /data
chmod 755 /datamodify vim /etc/exports
/data *(rw,sync,insecure,no_subtree_check,no_root_squash)start nfs server
systemctl start rpcbind
systemctl start nfs-server
systemctl enable rpcbind
systemctl enable nfs-servercheck nfs server
showmount -e localhost
# Output
Export list for localhost:
/data *
- Install munge service
- add user munge
(All Nodes)
sudo apt install -y build-essential git wget munge libmunge-dev libmunge2 \
mariadb-server libmariadb-dev libssl-dev libpam0g-dev \
libhwloc-dev liblua5.3-dev libreadline-dev libncurses-dev \
libjson-c-dev libyaml-dev libhttp-parser-dev libjwt-dev libdbus-glib-1-dev libbpf-dev libdbus-1-dev
which mungekey
# 如果有,使用它生成 key
sudo systemctl stop munge
sudo mungekey -c
sudo chown munge:munge /etc/munge/munge.key
sudo chmod 400 /etc/munge/munge.key
sudo systemctl start munge- copy
munge.keyfrom manager node to the rest node(All Nodes)
sudo scp /etc/munge/munge.key juice-036:/tmp/munge.key
sudo scp /etc/munge/munge.key juice-037:/tmp/munge.key
sudo scp /etc/munge/munge.key juice-038:/tmp/munge.key- grant privilege on munge.key
(All Nodes)
systemctl stop munge
sudo mv /tmp/munge.key /etc/munge/munge.key
chown munge: /etc/munge/munge.key
chmod 400 /etc/munge/munge.key
systemctl start munge
systemctl status munge
systemctl enable mungeUsing systemctl status munge to check if the service is running
- test munge
munge -n | ssh juice-036 unmunge
munge -n | ssh juice-037 unmunge
munge -n | ssh juice-038 unmunge
- Install Mariadb
(Manager Nodes)
apt-get install -y mariadb-server- create database and user
systemctl start mariadb
systemctl enable mariadb
ROOT_PASS=$(tr -dc A-Za-z0-9 </dev/urandom | head -c 16)
mysql -e "CREATE USER root IDENTIFIED BY '${ROOT_PASS}'"
mysql -uroot -p$ROOT_PASS -e 'create database slurm_acct_db'- create user
slurm,and grant all privileges on databaseslurm_acct_db
mysql -uroot -p$ROOT_PASScreate user slurm;
grant all on slurm_acct_db.* TO 'slurm'@'localhost' identified by '123456' with grant option;
flush privileges;- create Slurm user
groupadd -g 1109 slurm
useradd -m -c "Slurm manager" -d /var/lib/slurm -u 1109 -g slurm -s /bin/bash slurmInstall Slurm (All Nodes)
- Install basic Debian package build requirements:
apt-get install -y build-essential fakeroot devscripts equivs- Unpack the distributed tarball:
wget https://download.schedmd.com/slurm/slurm-25.05.2.tar.bz2 -O slurm-25.05.2.tar.bz2 &&
tar -xaf slurm*tar.bz2- cd to the directory containing the Slurm source:
cd slurm-25.05.2 && mkdir -p /etc/slurm && ./configure --prefix=/usr --sysconfdir=/etc/slurm --enable-cgroupv2- compile slurm
make installmodify configuration files
(Manager Nodes)- modify
/etc/slurm/slurm.confRefer to slurm.conf
cp /root/slurm-25.05.2/etc/slurm.conf.example /etc/slurm/slurm.conf vim /etc/slurm/slurm.conffocus on these options:
SlurmctldHost=manage AccountingStorageEnforce=associations,limits,qos AccountingStorageHost=manage AccountingStoragePass=/var/run/munge/munge.socket.2 AccountingStoragePort=6819 AccountingStorageType=accounting_storage/slurmdbd JobCompHost=localhost JobCompLoc=slurm_acct_db JobCompPass=123456 JobCompPort=3306 JobCompType=jobcomp/mysql JobCompUser=slurm JobContainerType=job_container/none JobAcctGatherType=jobacct_gather/linux- modify
/etc/slurm/slurmdbd.confRefer to slurmdbd.conf
cp /root/slurm-25.05.2/etc/slurmdbd.conf.example /etc/slurm/slurmdbd.conf vim /etc/slurm/slurmdbd.conf- modify
/etc/slurm/cgroup.conf
cp /root/slurm-25.05.2/etc/cgroup.conf.example /etc/slurm/cgroup.conf- send configuration files to other nodes
scp -r /etc/slurm/*.conf root@juice-037:/etc/slurm/ scp -r /etc/slurm/*.conf root@juice-038:/etc/slurm/- modify
grant privilege on some directories
(All Nodes)
mkdir /var/spool/slurmd
chown slurm: /var/spool/slurmd
mkdir /var/log/slurm
chown slurm: /var/log/slurm
mkdir /var/spool/slurmctld
chown slurm: /var/spool/slurmctld
chown slurm: /etc/slurm/slurmdbd.conf
chmod 600 /etc/slurm/slurmdbd.conf- start slurm services on each node
Node:
systemctl start slurmdbd
systemctl enable slurmdbd
systemctl start slurmctld
systemctl enable slurmctld
systemctl start slurmd
systemctl enable slurmd
systemctl start slurmd
systemctl enable slurmd
systemctl start slurmd
systemctl enable slurmd
systemctl start slurmd
systemctl enable slurmdTest Your Slurm Cluster (Login Node)
- check cluster configuration
scontrol show config- check cluster status
sinfo
scontrol show partition
scontrol show node- submit job
srun -N2 hostname
scontrol show jobs- check job status
check job status
squeue -aInstall From Binary
Important
(All Nodes) means all type nodes should install this component.
(Manager Node) means only the manager node should install this component.
(Login Node) means only the Auth node should install this component.
(Cmp) means only the Compute node should install this component.
Typically, there are three nodes are required to run Slurm.
1
Manage(Manager Node), 1Login Nodeand NCompute(Cmp).but you can choose to install all service in single node. check
Prequisites
- change hostname
(All Nodes)hostnamectl set-hostname (manager|auth|computeXX) - modify
/etc/hosts(All Nodes)echo "192.aa.bb.cc (manager|auth|computeXX)" >> /etc/hosts - disable firewall, selinux, dnsmasq, swap
(All Nodes). more detail here - NFS Server
(Manager Node). NFS is used as the default file system for the Slurm accounting database. - [NFS Client]
(All Nodes). all node should mount the NFS share - Munge
(All Nodes). The auth/munge plugin will be built if the MUNGE authentication development library is installed. MUNGE is used as the default authentication mechanism. - Database
(Manager Node). MySQL support for accounting will be built if the MySQL or MariaDB development library is present. A currently supported version of MySQL or MariaDB should be used.
Install Slurm
- create
slurmuser(All Nodes)groupadd -g 1109 slurm useradd -m -c "slurm manager" -d /var/lib/slurm -u 1109 -g slurm -s /bin/bash slurm
Install Slurm from
Build RPM package
install depeendencies
(Manager Node)yum -y install gcc gcc-c++ readline-devel perl-ExtUtils-MakeMaker pam-devel rpm-build mysql-devel python3build rpm package
(Manager Node)wget https://download.schedmd.com/slurm/slurm-24.05.2.tar.bz2 -O slurm-24.05.2.tar.bz2 rpmbuild -ta --nodeps slurm-24.05.2.tar.bz2The rpm files will be installed under the
$(HOME)/rpmbuilddirectory of the user building them.send rpm to rest nodes
(Manager Node)ssh root@<$rest_node> "mkdir -p /root/rpmbuild/RPMS/" scp -p $(HOME)/rpmbuild/RPMS/x86_64 root@<$rest_node>:/root/rpmbuild/RPMS/x86_64install rpm
(Manager Node)ssh root@<$rest_node> "yum localinstall /root/rpmbuild/RPMS/x86_64/slurm-*"modify configuration file
(Manager Node)cp /etc/slurm/cgroup.conf.example /etc/slurm/cgroup.conf cp /etc/slurm/slurm.conf.example /etc/slurm/slurm.conf cp /etc/slurm/slurmdbd.conf.example /etc/slurm/slurmdbd.conf chmod 600 /etc/slurm/slurmdbd.conf chown slurm: /etc/slurm/slurmdbd.confcgroup.confdoesnt need to change.edit
/etc/slurm/slurm.conf, you can use this link as a referenceedit
/etc/slurm/slurmdbd.conf, you can use this link as a reference
Install yum repo directly
install slurm
(All Nodes)yum -y slurm-wlm slurmdbdmodify configuration file
(All Nodes)vim /etc/slurm-llnl/slurm.confvim /etc/slurm-llnl/slurmdbd.confcgroup.confdoesnt need to change.edit
/etc/slurm/slurm.conf, you can use this link as a referenceedit
/etc/slurm/slurmdbd.conf, you can use this link as a reference
- send configuration
(Manager Node)scp -r /etc/slurm/*.conf root@<$rest_node>:/etc/slurm/ ssh rootroot@<$rest_node> "mkdir /var/spool/slurmd && chown slurm: /var/spool/slurmd" ssh rootroot@<$rest_node> "mkdir /var/log/slurm && chown slurm: /var/log/slurm" ssh rootroot@<$rest_node> "mkdir /var/spool/slurmctld && chown slurm: /var/spool/slurmctld" - start service
(Manager Node)ssh rootroot@<$rest_node> "systemctl start slurmdbd && systemctl enable slurmdbd" ssh rootroot@<$rest_node> "systemctl start slurmctld && systemctl enable slurmctld" - start service
(All Nodes)ssh rootroot@<$rest_node> "systemctl start slurmd && systemctl enable slurmd"
Test
- show cluster status
scontrol show configsinfo
scontrol show partition
scontrol show node- submit job
srun -N2 hostname
scontrol show jobs- check job status
squeue -aReference:
Install From Helm Chart
Despite the complex binary installation, helm chart is a better way to install slurm.
Source code could be found from https://github.com/AaronYang0628/slurm-on-k8s
Prequisites
Installation
get helm repo and update
helm repo add ay-helm-mirror https://aaronyang0628.github.io/helm-chart-mirror/chartsinstall slurm chart
# wget -O slurm.values.yaml https://raw.githubusercontent.com/AaronYang0628/slurm-on-k8s/refs/heads/main/chart/values.yaml helm install slurm ay-helm-mirror/chart -f slurm.values.yaml --version 1.0.10Or you can get template values.yaml from https://raw.githubusercontent.com/AaronYang0628/helm-chart-mirror/refs/heads/main/templates/slurm/slurm.values.yaml
check chart status
helm -n slurm list
Install From K8s Operator
Despite the complex binary installation, using k8s operator is a better way to install slurm.
Source code could be found from https://github.com/AaronYang0628/slurm-on-k8s
Prequisites
Installation
deploy slurm operator
kubectl apply -f https://raw.githubusercontent.com/AaronYang0628/helm-chart-mirror/refs/heads/main/templates/slurm/operator_install.yamlcheck operator status
kubectl -n slurm get podapply CRD slurmdeployment
kubectl apply -f https://raw.githubusercontent.com/AaronYang0628/helm-chart-mirror/refs/heads/main/templates/slurm/slurmdeployment.zj.values.yamlcheck operator status
kubectl get slurmdeployment kubectl -n slurm logs -f deploy/slurm-operator-controller-manager # kubectl get slurmdep # kubectl -n test get podsupgrade slurmdep
kubectl edit slurmdep lensing # set SlurmCPU.replicas = 3
Try OpenSCOW
What is SCOW?
SCOW is a HPC cluster management system built by PKU.
SCOW used four virtual machines to run slurm cluster. It is a good choice for you to learn how to use slurm.
You should check https://pkuhpc.github.io/OpenSCOW/docs/hpccluster, it works well.
CheatSheet
Subsections of CheatSheet
Common Environment Variables
| Variable | Description |
|---|---|
| $SLURM_JOB_ID | The Job ID. |
| $SLURM_JOBID | Deprecated. Same as $SLURM_JOB_ID |
| $SLURM_SUBMIT_HOST | The hostname of the node used for job submission. |
| $SLURM_JOB_NODELIST | Contains the definition (list) of the nodes that is assigned to the job. |
| $SLURM_NODELIST | Deprecated. Same as SLURM_JOB_NODELIST. |
| $SLURM_CPUS_PER_TASK | Number of CPUs per task. |
| $SLURM_CPUS_ON_NODE | Number of CPUs on the allocated node. |
| $SLURM_JOB_CPUS_PER_NODE | Count of processors available to the job on this node. |
| $SLURM_CPUS_PER_GPU | Number of CPUs requested per allocated GPU. |
| $SLURM_MEM_PER_CPU | Memory per CPU. Same as –mem-per-cpu . |
| $SLURM_MEM_PER_GPU | Memory per GPU. |
| $SLURM_MEM_PER_NODE | Memory per node. Same as –mem . |
| $SLURM_GPUS | Number of GPUs requested. |
| $SLURM_NTASKS | Same as -n, –ntasks. The number of tasks. |
| $SLURM_NTASKS_PER_NODE | Number of tasks requested per node. |
| $SLURM_NTASKS_PER_SOCKET | Number of tasks requested per socket. |
| $SLURM_NTASKS_PER_CORE | Number of tasks requested per core. |
| $SLURM_NTASKS_PER_GPU | Number of tasks requested per GPU. |
| $SLURM_NPROCS | Same as -n, –ntasks. See $SLURM_NTASKS. |
| $SLURM_TASKS_PER_NODE | Number of tasks to be initiated on each node. |
| $SLURM_ARRAY_JOB_ID | Job array’s master job ID number. |
| $SLURM_ARRAY_TASK_ID | Job array ID (index) number. |
| $SLURM_ARRAY_TASK_COUNT | Total number of tasks in a job array. |
| $SLURM_ARRAY_TASK_MAX | Job array’s maximum ID (index) number. |
| $SLURM_ARRAY_TASK_MIN | Job array’s minimum ID (index) number. |
A full list of environment variables for SLURM can be found by visiting the SLURM page on environment variables.
File Operations
File Distribution
sbcastis used to transfer a file from local disk to local disk on the nodes allocated to a job. This can be used to effectively use diskless compute nodes or provide improved performance relative to a shared file system.- Feature
distribute file:Quickly copy files to all compute nodes assigned to the job, avoiding the hassle of manually distributing files. Faster than traditional scp or rsync, especially when distributing to multiple nodes。simplify script:one command to distribute files to all nodes assigned to the job。imrpove performance:Improve file distribution speed by parallelizing transfers, especially for large or multiple files。
- Usage
- Alone
sbcast <source_file> <destination_path>- Embedded in a job script
#!/bin/bash #SBATCH --job-name=example_job #SBATCH --output=example_job.out #SBATCH --error=example_job.err #SBATCH --partition=compute #SBATCH --nodes=4 # Use sbcast to distribute the file to the /tmp directory of each node sbcast data.txt /tmp/data.txt # Run your program using the distributed files srun my_program /tmp/data.txt
- Feature
File Collection
File Redirection When submitting a job, you can use the #SBATCH –output and #SBATCH –error directives to redirect standard output and standard error to specified files.
#SBATCH --output=output.txt #SBATCH --error=error.txtOr
sbatch -N2 -w "compute[01-02]" -o result/file/path xxx.slurmSend the destination address manually Using
scporrsyncin the job to copy the files from the compute nodes to the submit nodeUsing NFS If a shared file system (such as NFS, Lustre, or GPFS) is configured in the computing cluster, the result files can be written directly to the shared directory. In this way, the result files generated by all nodes are automatically stored in the same location.
Using
sbcast
Submit Jobs
3 Type Jobs
srunis used to submit a job for execution or initiate job steps in real time.- Example
- run shell
srun -N2 bin/hostname- run script
srun -N1 test.sh- exec into slurmd node
srun -w slurm-lensing-slurm-slurmd-cpu-2 --pty /bin/bash
- Example
sbatchis used to submit a job script for later execution. The script will typically contain one or more srun commands to launch parallel tasks.- submit a batch job
sbatch -N2 -w "compute[01-02]" -o job.stdout /data/jobs/batch-job.slurm- submit a parallel task to process differnt data partition
sbatch /data/jobs/parallel.slurm
sallocis used to allocate resources for a job in real time. Typically this is used to allocate resources and spawn a shell. The shell is then used to execute srun commands to launch parallel tasks.- Example
- allocate resources (more like create an virtual machine)
This command will create a job which allocates 2 nodes and spawn a bash shell on each node. and you can execute srun commands in that environment. After your computing task is finsihs, remember to shutdown your job.salloc -N2 bashwhen you exit the job, the resources will be released.scancel <$job_id>
- Example
Configuration Files
MPI Libs
Subsections of MPI Libs
Test Intel MPI Jobs
在SLURM集群中使用MPI(Message Passing Interface)进行并行计算,通常需要以下几个步骤:
1. 安装MPI库
确保你的集群节点已经安装了MPI库,常见的MPI实现包括:
- OpenMPI
- Intel MPI
- MPICH 可以通过以下命令检查集群是否安装了MPI:
mpicc --version # 检查MPI编译器
mpirun --version # 检查MPI运行时环境2. 测试MPI性能
mpirun -n 2 IMB-MPI1 pingpong3. 编译MPI程序
你可以用mpicc(C语言)或mpic++(C++语言)来编译MPI程序。例如:
以下是一个简单的MPI “Hello, World!” 示例程序,假设文件名为 hello_mpi.c, 还有一个进行矩阵计算的示例程序,文件名为dot_product.c,任意挑选一个即可:
#include <stdio.h>
#include <mpi.h>
int main(int argc, char *argv[]) {
int rank, size;
// 初始化MPI环境
MPI_Init(&argc, &argv);
// 获取当前进程的rank和总进程数
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
// 输出进程的信息
printf("Hello, World! I am process %d out of %d processes.\n", rank, size);
// 退出MPI环境
MPI_Finalize();
return 0;
}#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
#define N 8 // 向量大小
// 计算向量的局部点积
double compute_local_dot_product(double *A, double *B, int start, int end) {
double local_dot = 0.0;
for (int i = start; i < end; i++) {
local_dot += A[i] * B[i];
}
return local_dot;
}
void print_vector(double *Vector) {
for (int i = 0; i < N; i++) {
printf("%f ", Vector[i]);
}
printf("\n");
}
int main(int argc, char *argv[]) {
int rank, size;
// 初始化MPI环境
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
// 向量A和B
double A[N], B[N];
// 进程0初始化向量A和B
if (rank == 0) {
for (int i = 0; i < N; i++) {
A[i] = i + 1; // 示例数据
B[i] = (i + 1) * 2; // 示例数据
}
}
// 广播向量A和B到所有进程
MPI_Bcast(A, N, MPI_DOUBLE, 0, MPI_COMM_WORLD);
MPI_Bcast(B, N, MPI_DOUBLE, 0, MPI_COMM_WORLD);
// 每个进程计算自己负责的部分
int local_n = N / size; // 每个进程处理的元素个数
int start = rank * local_n;
int end = (rank + 1) * local_n;
// 如果是最后一个进程,确保处理所有剩余的元素(处理N % size)
if (rank == size - 1) {
end = N;
}
double local_dot_product = compute_local_dot_product(A, B, start, end);
// 使用MPI_Reduce将所有进程的局部点积结果汇总到进程0
double global_dot_product = 0.0;
MPI_Reduce(&local_dot_product, &global_dot_product, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
// 进程0输出最终结果
if (rank == 0) {
printf("Vector A is\n");
print_vector(A);
printf("Vector B is\n");
print_vector(B);
printf("Dot Product of A and B: %f\n", global_dot_product);
}
// 结束MPI环境
MPI_Finalize();
return 0;
}3. 创建Slurm作业脚本
创建一个SLURM作业脚本来运行该MPI程序。以下是一个基本的SLURM作业脚本,假设文件名为 mpi_test.slurm:
#!/bin/bash
#SBATCH --job-name=mpi_job # Job name
#SBATCH --nodes=2 # Number of nodes to use
#SBATCH --ntasks-per-node=1 # Number of tasks per node
#SBATCH --time=00:10:00 # Time limit
#SBATCH --output=mpi_test_output_%j.log # Standard output file
#SBATCH --error=mpi_test_output_%j.err # Standard error file
# Manually set Intel OneAPI MPI and Compiler environment
export I_MPI_PMI=pmi2
export I_MPI_PMI_LIBRARY=/usr/lib/x86_64-linux-gnu/slurm/mpi_pmi2.so
export I_MPI_ROOT=/opt/intel/oneapi/mpi/2021.14
export INTEL_COMPILER_ROOT=/opt/intel/oneapi/compiler/2025.0
export PATH=$I_MPI_ROOT/bin:$INTEL_COMPILER_ROOT/bin:$PATH
export LD_LIBRARY_PATH=$I_MPI_ROOT/lib:$INTEL_COMPILER_ROOT/lib:$LD_LIBRARY_PATH
export MANPATH=$I_MPI_ROOT/man:$INTEL_COMPILER_ROOT/man:$MANPATH
# Compile the MPI program
icx-cc -I$I_MPI_ROOT/include hello_mpi.c -o hello_mpi -L$I_MPI_ROOT/lib -lmpi
# Run the MPI job
mpirun -np 2 ./hello_mpi#!/bin/bash
#SBATCH --job-name=mpi_job # Job name
#SBATCH --nodes=2 # Number of nodes to use
#SBATCH --ntasks-per-node=1 # Number of tasks per node
#SBATCH --time=00:10:00 # Time limit
#SBATCH --output=mpi_test_output_%j.log # Standard output file
#SBATCH --error=mpi_test_output_%j.err # Standard error file
# Manually set Intel OneAPI MPI and Compiler environment
export I_MPI_PMI=pmi2
export I_MPI_PMI_LIBRARY=/usr/lib/x86_64-linux-gnu/slurm/mpi_pmi2.so
export I_MPI_ROOT=/opt/intel/oneapi/mpi/2021.14
export INTEL_COMPILER_ROOT=/opt/intel/oneapi/compiler/2025.0
export PATH=$I_MPI_ROOT/bin:$INTEL_COMPILER_ROOT/bin:$PATH
export LD_LIBRARY_PATH=$I_MPI_ROOT/lib:$INTEL_COMPILER_ROOT/lib:$LD_LIBRARY_PATH
export MANPATH=$I_MPI_ROOT/man:$INTEL_COMPILER_ROOT/man:$MANPATH
# Compile the MPI program
icx-cc -I$I_MPI_ROOT/include dot_product.c -o dot_product -L$I_MPI_ROOT/lib -lmpi
# Run the MPI job
mpirun -np 2 ./dot_product4. 编译MPI程序
在运行作业之前,你需要编译MPI程序。在集群上使用mpicc来编译该程序。假设你将程序保存在 hello_mpi.c 文件中,使用以下命令进行编译:
mpicc -o hello_mpi hello_mpi.cmpicc -o dot_product dot_product.c5. 提交Slurm作业
保存上述作业脚本(mpi_test.slurm)并使用以下命令提交作业:
sbatch mpi_test.slurm6. 查看作业状态
你可以使用以下命令查看作业的状态:
squeue -u <your_username>7. 检查输出
作业完成后,输出将保存在你作业脚本中指定的文件中(例如 mpi_test_output_<job_id>.log)。你可以使用 cat 或任何文本编辑器查看输出:
cat mpi_test_output_*.log示例输出 如果一切正常,输出会类似于:
Hello, World! I am process 0 out of 2 processes.
Hello, World! I am process 1 out of 2 processes.Result Matrix C (A * B):
14 8 2 -4
20 10 0 -10
-1189958655 1552515295 21949 -1552471397
0 0 0 0 Test Open MPI Jobs
在SLURM集群中使用MPI(Message Passing Interface)进行并行计算,通常需要以下几个步骤:
1. 安装MPI库
确保你的集群节点已经安装了MPI库,常见的MPI实现包括:
- OpenMPI
- Intel MPI
- MPICH 可以通过以下命令检查集群是否安装了MPI:
mpicc --version # 检查MPI编译器
mpirun --version # 检查MPI运行时环境2. 编译MPI程序
你可以用mpicc(C语言)或mpic++(C++语言)来编译MPI程序。例如:
以下是一个简单的MPI “Hello, World!” 示例程序,假设文件名为 hello_mpi.c, 还有一个进行矩阵计算的示例程序,文件名为dot_product.c,任意挑选一个即可:
#include <stdio.h>
#include <mpi.h>
int main(int argc, char *argv[]) {
int rank, size;
// 初始化MPI环境
MPI_Init(&argc, &argv);
// 获取当前进程的rank和总进程数
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
// 输出进程的信息
printf("Hello, World! I am process %d out of %d processes.\n", rank, size);
// 退出MPI环境
MPI_Finalize();
return 0;
}#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
#define N 8 // 向量大小
// 计算向量的局部点积
double compute_local_dot_product(double *A, double *B, int start, int end) {
double local_dot = 0.0;
for (int i = start; i < end; i++) {
local_dot += A[i] * B[i];
}
return local_dot;
}
void print_vector(double *Vector) {
for (int i = 0; i < N; i++) {
printf("%f ", Vector[i]);
}
printf("\n");
}
int main(int argc, char *argv[]) {
int rank, size;
// 初始化MPI环境
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
// 向量A和B
double A[N], B[N];
// 进程0初始化向量A和B
if (rank == 0) {
for (int i = 0; i < N; i++) {
A[i] = i + 1; // 示例数据
B[i] = (i + 1) * 2; // 示例数据
}
}
// 广播向量A和B到所有进程
MPI_Bcast(A, N, MPI_DOUBLE, 0, MPI_COMM_WORLD);
MPI_Bcast(B, N, MPI_DOUBLE, 0, MPI_COMM_WORLD);
// 每个进程计算自己负责的部分
int local_n = N / size; // 每个进程处理的元素个数
int start = rank * local_n;
int end = (rank + 1) * local_n;
// 如果是最后一个进程,确保处理所有剩余的元素(处理N % size)
if (rank == size - 1) {
end = N;
}
double local_dot_product = compute_local_dot_product(A, B, start, end);
// 使用MPI_Reduce将所有进程的局部点积结果汇总到进程0
double global_dot_product = 0.0;
MPI_Reduce(&local_dot_product, &global_dot_product, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
// 进程0输出最终结果
if (rank == 0) {
printf("Vector A is\n");
print_vector(A);
printf("Vector B is\n");
print_vector(B);
printf("Dot Product of A and B: %f\n", global_dot_product);
}
// 结束MPI环境
MPI_Finalize();
return 0;
}3. 创建Slurm作业脚本
创建一个SLURM作业脚本来运行该MPI程序。以下是一个基本的SLURM作业脚本,假设文件名为 mpi_test.slurm:
#!/bin/bash
#SBATCH --job-name=mpi_test # 作业名称
#SBATCH --nodes=2 # 请求节点数
#SBATCH --ntasks-per-node=1 # 每个节点上的任务数
#SBATCH --time=00:10:00 # 最大运行时间
#SBATCH --output=mpi_test_output_%j.log # 输出日志文件
# 加载MPI模块(如果使用模块化环境)
module load openmpi
# 运行MPI程序
mpirun --allow-run-as-root -np 2 ./hello_mpi#!/bin/bash
#SBATCH --job-name=mpi_test # 作业名称
#SBATCH --nodes=2 # 请求节点数
#SBATCH --ntasks-per-node=1 # 每个节点上的任务数
#SBATCH --time=00:10:00 # 最大运行时间
#SBATCH --output=mpi_test_output_%j.log # 输出日志文件
# 加载MPI模块(如果使用模块化环境)
module load openmpi
# 运行MPI程序
mpirun --allow-run-as-root -np 2 ./dot_product4. 编译MPI程序
在运行作业之前,你需要编译MPI程序。在集群上使用mpicc来编译该程序。假设你将程序保存在 hello_mpi.c 文件中,使用以下命令进行编译:
mpicc -o hello_mpi hello_mpi.cmpicc -o dot_product dot_product.c5. 提交Slurm作业
保存上述作业脚本(mpi_test.slurm)并使用以下命令提交作业:
sbatch mpi_test.slurm6. 查看作业状态
你可以使用以下命令查看作业的状态:
squeue -u <your_username>7. 检查输出
作业完成后,输出将保存在你作业脚本中指定的文件中(例如 mpi_test_output_<job_id>.log)。你可以使用 cat 或任何文本编辑器查看输出:
cat mpi_test_output_*.log示例输出 如果一切正常,输出会类似于:
Hello, World! I am process 0 out of 2 processes.
Hello, World! I am process 1 out of 2 processes.Result Matrix C (A * B):
14 8 2 -4
20 10 0 -10
-1189958655 1552515295 21949 -1552471397
0 0 0 0