Rollout Example
Create the InferenceService
Follow the First Inference Service
tutorial. Set up a namespace kserve-test and create an InferenceService.
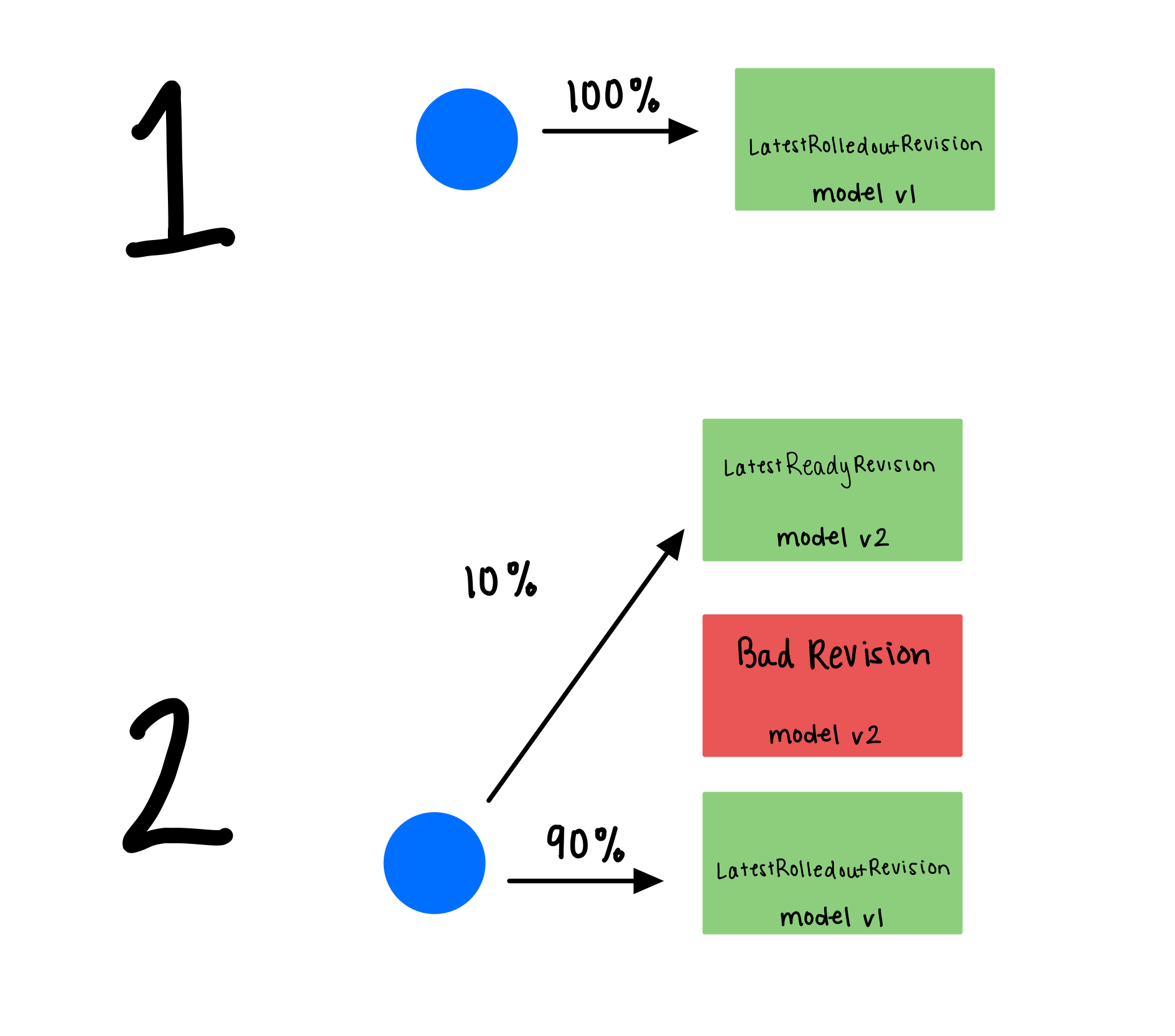
After rolling out the first model, 100% traffic goes to the initial model with service revision 1.
kubectl -n kserve-test get isvc sklearn-iris
Expectd Output
NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE
sklearn-iris http://sklearn-iris.kserve-test.example.com True 100 sklearn-iris-predictor--00001 46s 2m39s 70s
Apply Canary Rollout Strategy
- Add the
canaryTrafficPercent field to the predictor component - Update the
storageUri to use a new/updated model.
kubectl apply -n kserve-test -f - <<EOF
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "sklearn-iris"
namespace: kserve-test
spec:
predictor:
canaryTrafficPercent: 10
model:
args: ["--enable_docs_url=True"]
modelFormat:
name: sklearn
resources: {}
runtime: kserve-sklearnserver
storageUri: "gs://kfserving-examples/models/sklearn/1.0/model-2"
EOF
After rolling out the canary model, traffic is split between the latest ready revision 2 and the previously rolled out revision 1.
kubectl -n kserve-test get isvc sklearn-iris
Expectd Output
NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE
sklearn-iris http://sklearn-iris.kserve-test.example.com True 90 10 sklearn-iris-predictor-00002 sklearn-iris-predictor-00003 19h
Check the running pods, you should now see port two pods running for the old and new model and 10% traffic is routed to
the new model. Notice revision 1 contains 0002 in its name, while revision 2 contains 0003.
kubectl get pods
NAME READY STATUS RESTARTS AGE
sklearn-iris-predictor-00002-deployment-c7bb6c685-ktk7r 2/2 Running 0 71m
sklearn-iris-predictor-00003-deployment-8498d947-fpzcg 2/2 Running 0 20m
Run a prediction
Follow the next two
steps (Determine the ingress IP and ports and Perform inference) in
the First Inference Service tutorial.
Send more requests to the InferenceService to observe the 10% of traffic that routes to the new revision.
If the canary model is healthy/passes your tests,
you can promote it by removing the canaryTrafficPercent field and re-applying the InferenceService custom resource with the same name sklearn-iris
kubectl apply -n kserve-test -f - <<EOF
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "sklearn-iris"
namespace: kserve-test
spec:
predictor:
model:
args: ["--enable_docs_url=True"]
modelFormat:
name: sklearn
resources: {}
runtime: kserve-sklearnserver
storageUri: "gs://kfserving-examples/models/sklearn/1.0/model-2"
EOF
Now all traffic goes to the revision 2 for the new model.
kubectl get isvc sklearn-iris
NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE
sklearn-iris http://sklearn-iris.kserve-test.example.com True 100 sklearn-iris-predictor-00002 17m
The pods for revision generation 1 automatically scales down to 0 as it is no longer getting the traffic.
kubectl get pods -l serving.kserve.io/inferenceservice=sklearn-iris
NAME READY STATUS RESTARTS AGE
sklearn-iris-predictor-00001-deployment-66c5f5b8d5-gmfvj 1/2 Terminating 0 17m
sklearn-iris-predictor-00002-deployment-5bd9ff46f8-shtzd 2/2 Running 0 15m
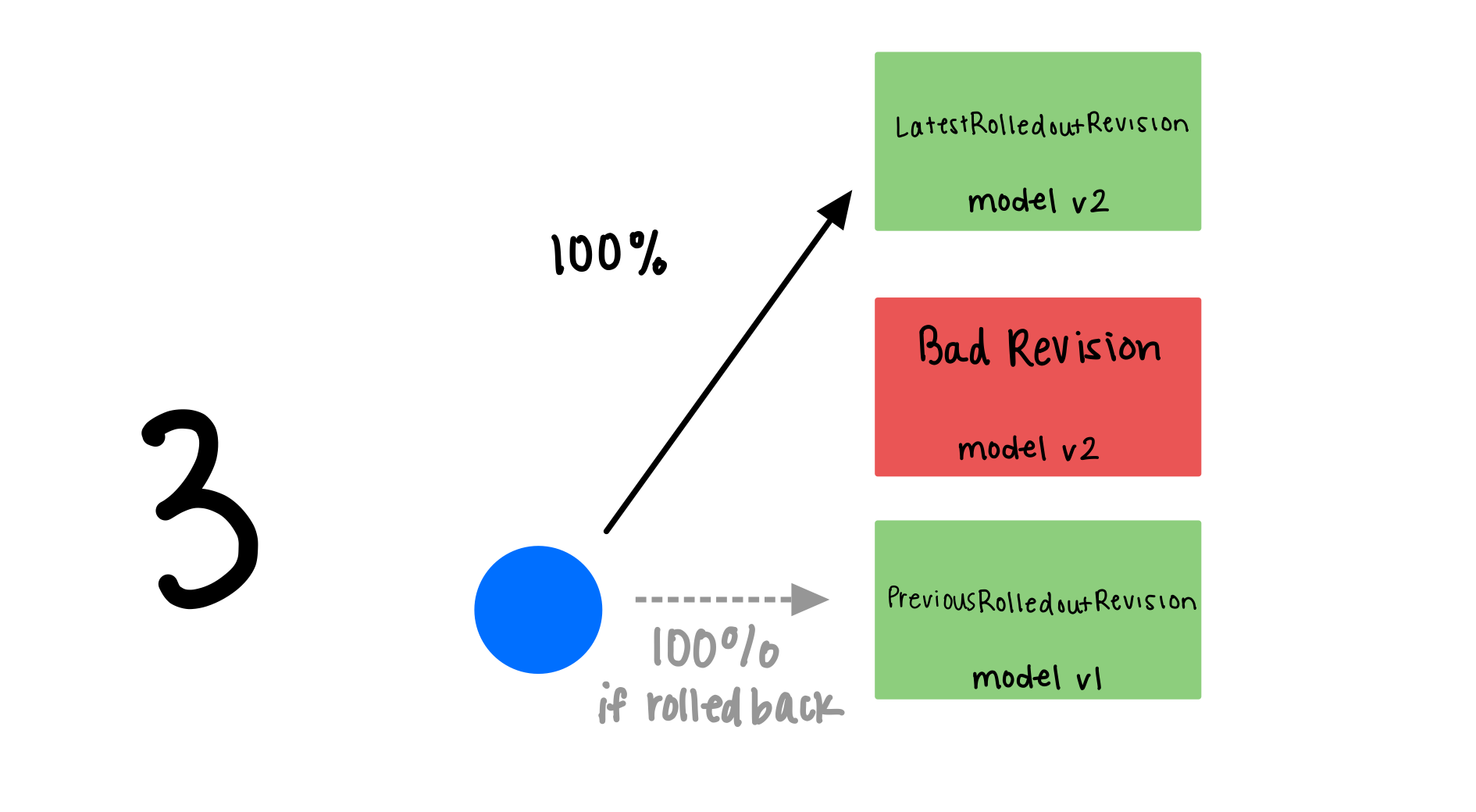
Rollback and pin the previous model
You can pin the previous model (model v1, for example) by setting the canaryTrafficPercent to 0 for the current
model (model v2, for example). This rolls back from model v2 to model v1 and decreases model v2’s traffic to zero.
Apply the custom resource to set model v2’s traffic to 0%.
kubectl apply -n kserve-test -f - <<EOF
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "sklearn-iris"
spec:
predictor:
canaryTrafficPercent: 0
model:
modelFormat:
name: sklearn
storageUri: "gs://kfserving-examples/models/sklearn/1.0/model-2"
EOF
Check the traffic split, now 100% traffic goes to the previous good model (model v1) for revision generation 1.
kubectl get isvc sklearn-iris
NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE
sklearn-iris http://sklearn-iris.kserve-test.example.com True 100 0 sklearn-iris-predictor-00002 sklearn-iris-predictor-00003 18m
The pods for previous revision (model v1) now routes 100% of the traffic to its pods while the new
model (model v2) routes 0% traffic to its pods.
kubectl get pods -l serving.kserve.io/inferenceservice=sklearn-iris
NAME READY STATUS RESTARTS AGE
sklearn-iris-predictor-00002-deployment-66c5f5b8d5-gmfvj 1/2 Running 0 35s
sklearn-iris-predictor-00003-deployment-5bd9ff46f8-shtzd 2/2 Running 0 16m
Route traffic using a tag
You can enable tag based routing by adding the annotation serving.kserve.io/enable-tag-routing, so traffic can be
explicitly routed to the canary model (model v2) or the old model (model v1) via a tag in the request URL.
Apply model v2 with canaryTrafficPercent: 10 and serving.kserve.io/enable-tag-routing: "true".
kubectl apply -n kserve-test -f - <<EOF
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "sklearn-iris"
annotations:
serving.kserve.io/enable-tag-routing: "true"
spec:
predictor:
canaryTrafficPercent: 10
model:
modelFormat:
name: sklearn
storageUri: "gs://kfserving-examples/models/sklearn/1.0/model-2"
EOF
Check the InferenceService status to get the canary and previous model URL.
kubectl get isvc sklearn-iris -ojsonpath="{.status.components.predictor}" | jq
The output should look like
Expectd Output
{
"address": {
"url": "http://sklearn-iris-predictor-.kserve-test.svc.cluster.local"
},
"latestCreatedRevision": "sklearn-iris-predictor--00003",
"latestReadyRevision": "sklearn-iris-predictor--00003",
"latestRolledoutRevision": "sklearn-iris-predictor--00001",
"previousRolledoutRevision": "sklearn-iris-predictor--00001",
"traffic": [
{
"latestRevision": true,
"percent": 10,
"revisionName": "sklearn-iris-predictor--00003",
"tag": "latest",
"url": "http://latest-sklearn-iris-predictor-.kserve-test.example.com"
},
{
"latestRevision": false,
"percent": 90,
"revisionName": "sklearn-iris-predictor--00001",
"tag": "prev",
"url": "http://prev-sklearn-iris-predictor-.kserve-test.example.com"
}
],
"url": "http://sklearn-iris-predictor-.kserve-test.example.com"
}
Since we updated the annotation on the InferenceService, model v2 now corresponds to sklearn-iris-predictor--00003.
You can now send the request explicitly to the new model or the previous model by using the tag in the request URL. Use
the curl command
from Perform inference and
add latest- or prev- to the model name to send a tag based request.
For example, set the model name and use the following commands to send traffic to each service based on the latest or prev tag.
curl the latest revision
MODEL_NAME=sklearn-iris
curl -v -H "Host: latest-${MODEL_NAME}-predictor-.kserve-test.example.com" -H "Content-Type: application/json" http://${INGRESS_HOST}:${INGRESS_PORT}/v1/models/$MODEL_NAME:predict -d @./iris-input.json
or curl the previous revision
curl -v -H "Host: prev-${MODEL_NAME}-predictor-.kserve-test.example.com" -H "Content-Type: application/json" http://${INGRESS_HOST}:${INGRESS_PORT}/v1/models/$MODEL_NAME:predict -d @./iris-input.json