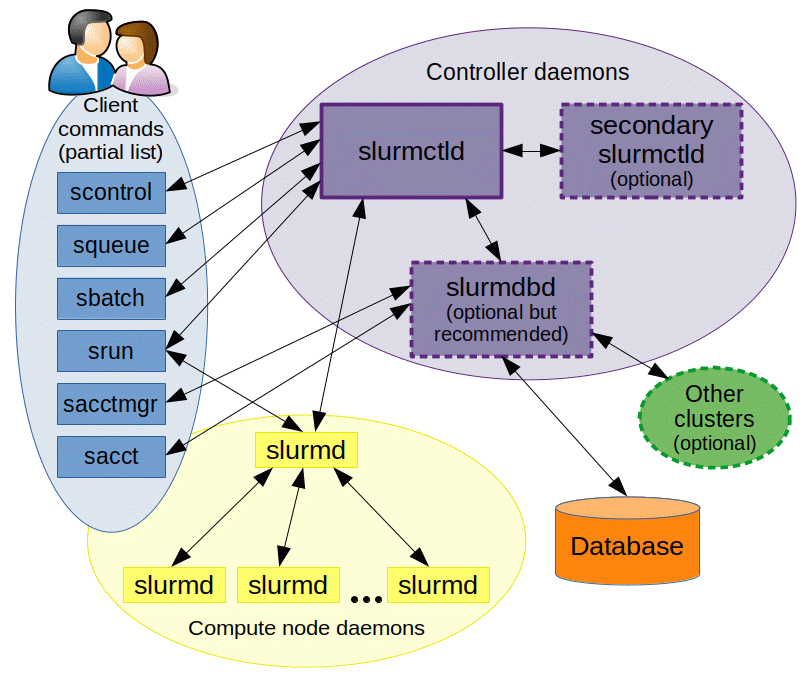
The Slurm Workload Manager, formerly known as Simple Linux Utility for Resource Management (SLURM), or simply Slurm, is a free and open-source job scheduler for Linux and Unix-like kernels, used by many of the world’s supercomputers and computer clusters.
It provides three key functions:
allocating exclusive and/or non-exclusive access to resources (computer nodes) to users for some duration of time so they can perform work,
providing a framework for starting, executing, and monitoring work, typically a parallel job such as Message Passing Interface (MPI) on a set of allocated nodes, and
arbitrating contention for resources by managing a queue of pending jobs.
What is SCOW? SCOW is a HPC cluster management system built by PKU.
SCOW used four virtual machines to run slurm cluster. It is a good choice for you to learn how to use slurm.
You should check https://pkuhpc.github.io/OpenSCOW/docs/hpccluster, it works well.
Subsections of Build & Install
Install On Debian
Cluster Setting
1 Manager
1 Login Node
2 Compute nodes
hostname
IP
role
quota
manage01 (slurmctld, slurmdbd)
192.168.56.115
manager
2C4G
login01 (login)
192.168.56.116
login
2C4G
compute01 (slurmd)
192.168.56.117
compute
2C4G
compute02 (slurmd)
192.168.56.118
compute
2C4G
Software Version:
software
version
os
Debian 12 bookworm
slurm
24.05.2
Important
when you see (All Nodes), you need to run the following command on all nodes
when you see (Manager Node), you only need to run the following command on manager node
when you see (Login Node), you only need to run the following command on login node
Prepare Steps (All Nodes)
Modify the /etc/apt/sources.list file
Using tuna mirror
cat > /etc/apt/sources.list << EOF
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm main contrib non-free non-free-firmware
deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm main contrib non-free non-free-firmware
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm-updates main contrib non-free non-free-firmware
deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm-updates main contrib non-free non-free-firmware
deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm-backports main contrib non-free non-free-firmware
deb-src https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm-backports main contrib non-free non-free-firmware
deb https://mirrors.tuna.tsinghua.edu.cn/debian-security/ bookworm-security main contrib non-free non-free-firmware
deb-src https://mirrors.tuna.tsinghua.edu.cn/debian-security/ bookworm-security main contrib non-free non-free-firmware
EOF
Using `systemctl status xxxx` to check if the `xxxx` service is running
Example slurmdbd.server
```text
# vim /usr/lib/systemd/system/slurmdbd.service
[Unit]
Description=Slurm DBD accounting daemon
After=network-online.target remote-fs.target munge.service mysql.service mysqld.service mariadb.service sssd.service
Wants=network-online.target
ConditionPathExists=/etc/slurm/slurmdbd.conf
[Service]
Type=simple
EnvironmentFile=-/etc/sysconfig/slurmdbd
EnvironmentFile=-/etc/default/slurmdbd
User=slurm
Group=slurm
RuntimeDirectory=slurmdbd
RuntimeDirectoryMode=0755
ExecStart=/usr/local/sbin/slurmdbd -D -s $SLURMDBD_OPTIONS
ExecReload=/bin/kill -HUP $MAINPID
LimitNOFILE=65536
# Uncomment the following lines to disable logging through journald.
# NOTE: It may be preferable to set these through an override file instead.
#StandardOutput=null
#StandardError=null
[Install]
WantedBy=multi-user.target
```
Example slumctld.server
```text
# vim /usr/lib/systemd/system/slurmctld.service
[Unit]
Description=Slurm controller daemon
After=network-online.target remote-fs.target munge.service sssd.service
Wants=network-online.target
ConditionPathExists=/etc/slurm/slurm.conf
[Service]
Type=notify
EnvironmentFile=-/etc/sysconfig/slurmctld
EnvironmentFile=-/etc/default/slurmctld
User=slurm
Group=slurm
RuntimeDirectory=slurmctld
RuntimeDirectoryMode=0755
ExecStart=/usr/local/sbin/slurmctld --systemd $SLURMCTLD_OPTIONS
ExecReload=/bin/kill -HUP $MAINPID
LimitNOFILE=65536
# Uncomment the following lines to disable logging through journald.
# NOTE: It may be preferable to set these through an override file instead.
#StandardOutput=null
#StandardError=null
[Install]
WantedBy=multi-user.target
```
Example slumd.server
```text
# vim /usr/lib/systemd/system/slurmd.service
[Unit]
Description=Slurm node daemon
After=munge.service network-online.target remote-fs.target sssd.service
Wants=network-online.target
#ConditionPathExists=/etc/slurm/slurm.conf
[Service]
Type=notify
EnvironmentFile=-/etc/sysconfig/slurmd
EnvironmentFile=-/etc/default/slurmd
RuntimeDirectory=slurm
RuntimeDirectoryMode=0755
ExecStart=/usr/local/sbin/slurmd --systemd $SLURMD_OPTIONS
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
LimitNOFILE=131072
LimitMEMLOCK=infinity
LimitSTACK=infinity
Delegate=yes
# Uncomment the following lines to disable logging through journald.
# NOTE: It may be preferable to set these through an override file instead.
#StandardOutput=null
#StandardError=null
[Install]
WantedBy=multi-user.target
```
systemctl start slurmd
systemctl enable slurmd
Using `systemctl status slurmd` to check if the `slurmd` service is running
systemctl start slurmd
systemctl enable slurmd
Using `systemctl status slurmd` to check if the `slurmd` service is running
systemctl start slurmd
systemctl enable slurmd
Using `systemctl status slurmd` to check if the `slurmd` service is running
Test Your Slurm Cluster (Login Node)
check cluster configuration
scontrol show config
check cluster status
sinfo
scontrol show partition
scontrol show node
submit job
srun -N2 hostname
scontrol show jobs
check job status
check job status
squeue -a
Install On Ubuntu
Cluster Setting
1 Manager
1 Login Node
2 Compute nodes
hostname
IP
role
quota
manage01 (slurmctld, slurmdbd)
192.168.56.115
manager
2C4G
login01 (login)
192.168.56.116
login
2C4G
compute01 (slurmd)
192.168.56.117
compute
2C4G
compute02 (slurmd)
192.168.56.118
compute
2C4G
Software Version:
software
version
os
Ubuntu 22.04
slurm
24.05.2
Important
when you see (All Nodes), you need to run the following command on all nodes
when you see (Manager Node), you only need to run the following command on manager node
when you see (Login Node), you only need to run the following command on login node
Prepare Steps (All Nodes)
Modify the /etc/apt/sources.list file
Using tuna mirror
Using `systemctl status xxxx` to check if the `xxxx` service is running
Example slurmdbd.server
```text
# vim /usr/lib/systemd/system/slurmdbd.service
[Unit]
Description=Slurm DBD accounting daemon
After=network-online.target remote-fs.target munge.service mysql.service mysqld.service mariadb.service sssd.service
Wants=network-online.target
ConditionPathExists=/etc/slurm/slurmdbd.conf
[Service]
Type=simple
EnvironmentFile=-/etc/sysconfig/slurmdbd
EnvironmentFile=-/etc/default/slurmdbd
User=slurm
Group=slurm
RuntimeDirectory=slurmdbd
RuntimeDirectoryMode=0755
ExecStart=/usr/sbin/slurmdbd -D -s $SLURMDBD_OPTIONS
ExecReload=/bin/kill -HUP $MAINPID
LimitNOFILE=65536
# Uncomment the following lines to disable logging through journald.
# NOTE: It may be preferable to set these through an override file instead.
#StandardOutput=null
#StandardError=null
[Install]
WantedBy=multi-user.target
```
Example slumctld.server
```text
# vim /usr/lib/systemd/system/slurmctld.service
[Unit]
Description=Slurm controller daemon
After=network-online.target remote-fs.target munge.service sssd.service
Wants=network-online.target
ConditionPathExists=/etc/slurm/slurm.conf
[Service]
Type=notify
EnvironmentFile=-/etc/sysconfig/slurmctld
EnvironmentFile=-/etc/default/slurmctld
User=slurm
Group=slurm
RuntimeDirectory=slurmctld
RuntimeDirectoryMode=0755
ExecStart=/usr/sbin/slurmctld --systemd $SLURMCTLD_OPTIONS
ExecReload=/bin/kill -HUP $MAINPID
LimitNOFILE=65536
# Uncomment the following lines to disable logging through journald.
# NOTE: It may be preferable to set these through an override file instead.
#StandardOutput=null
#StandardError=null
[Install]
WantedBy=multi-user.target
```
Example slumd.server
```text
# vim /usr/lib/systemd/system/slurmd.service
[Unit]
Description=Slurm node daemon
After=munge.service network-online.target remote-fs.target sssd.service
Wants=network-online.target
#ConditionPathExists=/etc/slurm/slurm.conf
[Service]
Type=notify
EnvironmentFile=-/etc/sysconfig/slurmd
EnvironmentFile=-/etc/default/slurmd
RuntimeDirectory=slurm
RuntimeDirectoryMode=0755
ExecStart=/usr/sbin/slurmd --systemd $SLURMD_OPTIONS
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
LimitNOFILE=131072
LimitMEMLOCK=infinity
LimitSTACK=infinity
Delegate=yes
# Uncomment the following lines to disable logging through journald.
# NOTE: It may be preferable to set these through an override file instead.
#StandardOutput=null
#StandardError=null
[Install]
WantedBy=multi-user.target
```
systemctl start slurmd
systemctl enable slurmd
Using `systemctl status slurmd` to check if the `slurmd` service is running
systemctl start slurmd
systemctl enable slurmd
Using `systemctl status slurmd` to check if the `slurmd` service is running
systemctl start slurmd
systemctl enable slurmd
Using `systemctl status slurmd` to check if the `slurmd` service is running
Test Your Slurm Cluster (Login Node)
check cluster configuration
scontrol show config
check cluster status
sinfo
scontrol show partition
scontrol show node
submit job
srun -N2 hostname
scontrol show jobs
check job status
check job status
squeue -a
Install From Binary
Important
(All Nodes) means all type nodes should install this component.
(Manager Node) means only the manager node should install this component.
(Login Node) means only the Auth node should install this component.
(Cmp) means only the Compute node should install this component.
Typically, there are three nodes are required to run Slurm.
1 Manage(Manager Node), 1 Login Node and N Compute(Cmp).
but you can choose to install all service in single node. check
disable firewall, selinux, dnsmasq, swap (All Nodes). more detail here
NFS Server(Manager Node). NFS is used as the default file system for the Slurm accounting database.
[NFS Client] (All Nodes). all node should mount the NFS share
Install NFS Client
mount <$nfs_server>:/data /data -o proto=tcp -o nolock
Munge(All Nodes). The auth/munge plugin will be built if the MUNGE authentication development library is installed. MUNGE is used as the default authentication mechanism.
Install Munge
Database (Manager Node). MySQL support for accounting will be built if the MySQL or MariaDB development library is present. A currently supported version of MySQL or MariaDB should be used.
Install MariaDB
install mariadb
yum -y install mariadb-server
systemctl start mariadb && systemctl enable mariadb
ROOT_PASS=$(tr -dc A-Za-z0-9 </dev/urandom | head -c 16)mysql -e "CREATE USER root IDENTIFIED BY '${ROOT_PASS}'"
[root@ay-zj-ecs operator]# kubectl apply -f https://raw.githubusercontent.com/AaronYang0628/helm-chart-mirror/refs/heads/main/templates/slurm/operator_install.yamlnamespace/slurm created
customresourcedefinition.apiextensions.k8s.io/slurmdeployments.slurm.ay.dev created
serviceaccount/slurm-operator-controller-manager created
role.rbac.authorization.k8s.io/slurm-operator-leader-election-role created
clusterrole.rbac.authorization.k8s.io/slurm-operator-manager-role created
clusterrole.rbac.authorization.k8s.io/slurm-operator-metrics-auth-role created
clusterrole.rbac.authorization.k8s.io/slurm-operator-metrics-reader created
clusterrole.rbac.authorization.k8s.io/slurm-operator-slurmdeployment-admin-role created
clusterrole.rbac.authorization.k8s.io/slurm-operator-slurmdeployment-editor-role created
clusterrole.rbac.authorization.k8s.io/slurm-operator-slurmdeployment-viewer-role created
rolebinding.rbac.authorization.k8s.io/slurm-operator-leader-election-rolebinding created
clusterrolebinding.rbac.authorization.k8s.io/slurm-operator-manager-rolebinding created
clusterrolebinding.rbac.authorization.k8s.io/slurm-operator-metrics-auth-rolebinding created
service/slurm-operator-controller-manager-metrics-service created
deployment.apps/slurm-operator-controller-manager created
check operator status
kubectl -n slurm get pod
Expectd Output
[root@ay-zj-ecs operator]# kubectl -n slurm get podNAME READY STATUS RESTARTS AGE
slurm-operator-controller-manager 1/1 Running 0 27s
Contains the definition (list) of the nodes that is assigned to the job.
$SLURM_NODELIST
Deprecated. Same as SLURM_JOB_NODELIST.
$SLURM_CPUS_PER_TASK
Number of CPUs per task.
$SLURM_CPUS_ON_NODE
Number of CPUs on the allocated node.
$SLURM_JOB_CPUS_PER_NODE
Count of processors available to the job on this node.
$SLURM_CPUS_PER_GPU
Number of CPUs requested per allocated GPU.
$SLURM_MEM_PER_CPU
Memory per CPU. Same as –mem-per-cpu .
$SLURM_MEM_PER_GPU
Memory per GPU.
$SLURM_MEM_PER_NODE
Memory per node. Same as –mem .
$SLURM_GPUS
Number of GPUs requested.
$SLURM_NTASKS
Same as -n, –ntasks. The number of tasks.
$SLURM_NTASKS_PER_NODE
Number of tasks requested per node.
$SLURM_NTASKS_PER_SOCKET
Number of tasks requested per socket.
$SLURM_NTASKS_PER_CORE
Number of tasks requested per core.
$SLURM_NTASKS_PER_GPU
Number of tasks requested per GPU.
$SLURM_NPROCS
Same as -n, –ntasks. See $SLURM_NTASKS.
$SLURM_TASKS_PER_NODE
Number of tasks to be initiated on each node.
$SLURM_ARRAY_JOB_ID
Job array’s master job ID number.
$SLURM_ARRAY_TASK_ID
Job array ID (index) number.
$SLURM_ARRAY_TASK_COUNT
Total number of tasks in a job array.
$SLURM_ARRAY_TASK_MAX
Job array’s maximum ID (index) number.
$SLURM_ARRAY_TASK_MIN
Job array’s minimum ID (index) number.
A full list of environment variables for SLURM can be found by visiting the SLURM page on environment variables.
File Operations
File Distribution
sbcast
is used to transfer a file from local disk to local disk on the nodes allocated to a job. This can be used to effectively use diskless compute nodes or provide improved performance relative to a shared file system.
distribute file:Quickly copy files to all compute nodes assigned to the job, avoiding the hassle of manually distributing files. Faster than traditional scp or rsync, especially when distributing to multiple nodes。
simplify script:one command to distribute files to all nodes assigned to the job。
imrpove performance:Improve file distribution speed by parallelizing transfers, especially for large or multiple files。
#!/bin/bash
#SBATCH --job-name=example_job#SBATCH --output=example_job.out#SBATCH --error=example_job.err#SBATCH --partition=compute#SBATCH --nodes=4# Use sbcast to distribute the file to the /tmp directory of each nodesbcast data.txt /tmp/data.txt
# Run your program using the distributed filessrun my_program /tmp/data.txt
File Collection
File Redirection
When submitting a job, you can use the #SBATCH –output and #SBATCH –error directives to redirect standard output and standard error to specified files.
Send the destination address manually
Using scp or rsync in the job to copy the files from the compute nodes to the submit node
Using NFS
If a shared file system (such as NFS, Lustre, or GPFS) is configured in the computing cluster, the result files can be written directly to the shared directory. In this way, the result files generated by all nodes are automatically stored in the same location.
Using sbcast
Submit Jobs
3 Type Jobs
srun
is used to submit a job for execution or initiate job steps in real time.
salloc
is used to allocate resources for a job in real time. Typically this is used to allocate resources and spawn a shell. The shell is then used to execute srun commands to launch parallel tasks.
allocate resources (more like create an virtual machine)
salloc -N2 bash
This command will create a job which allocates 2 nodes and spawn a bash shell on each node. and you can execute srun commands in that environment. After your computing task is finsihs, remember to shutdown your job.
scancel <$job_id>
when you exit the job, the resources will be released.
#include<stdio.h>#include<mpi.h>intmain(intargc,char*argv[]){intrank,size;// 初始化MPI环境
MPI_Init(&argc,&argv);// 获取当前进程的rank和总进程数
MPI_Comm_rank(MPI_COMM_WORLD,&rank);MPI_Comm_size(MPI_COMM_WORLD,&size);// 输出进程的信息
printf("Hello, World! I am process %d out of %d processes.\n",rank,size);// 退出MPI环境
MPI_Finalize();return0;}
#include<stdio.h>#include<stdlib.h>#include<mpi.h>#define N 8 // 向量大小
// 计算向量的局部点积
doublecompute_local_dot_product(double*A,double*B,intstart,intend){doublelocal_dot=0.0;for(inti=start;i<end;i++){local_dot+=A[i]*B[i];}returnlocal_dot;}voidprint_vector(double*Vector){for(inti=0;i<N;i++){printf("%f ",Vector[i]);}printf("\n");}intmain(intargc,char*argv[]){intrank,size;// 初始化MPI环境
MPI_Init(&argc,&argv);MPI_Comm_rank(MPI_COMM_WORLD,&rank);MPI_Comm_size(MPI_COMM_WORLD,&size);// 向量A和B
doubleA[N],B[N];// 进程0初始化向量A和B
if(rank==0){for(inti=0;i<N;i++){A[i]=i+1;// 示例数据
B[i]=(i+1)*2;// 示例数据
}}// 广播向量A和B到所有进程
MPI_Bcast(A,N,MPI_DOUBLE,0,MPI_COMM_WORLD);MPI_Bcast(B,N,MPI_DOUBLE,0,MPI_COMM_WORLD);// 每个进程计算自己负责的部分
intlocal_n=N/size;// 每个进程处理的元素个数
intstart=rank*local_n;intend=(rank+1)*local_n;// 如果是最后一个进程,确保处理所有剩余的元素(处理N % size)
if(rank==size-1){end=N;}doublelocal_dot_product=compute_local_dot_product(A,B,start,end);// 使用MPI_Reduce将所有进程的局部点积结果汇总到进程0
doubleglobal_dot_product=0.0;MPI_Reduce(&local_dot_product,&global_dot_product,1,MPI_DOUBLE,MPI_SUM,0,MPI_COMM_WORLD);// 进程0输出最终结果
if(rank==0){printf("Vector A is\n");print_vector(A);printf("Vector B is\n");print_vector(B);printf("Dot Product of A and B: %f\n",global_dot_product);}// 结束MPI环境
MPI_Finalize();return0;}
#!/bin/bash
#SBATCH --job-name=mpi_job # Job name#SBATCH --nodes=2 # Number of nodes to use#SBATCH --ntasks-per-node=1 # Number of tasks per node#SBATCH --time=00:10:00 # Time limit#SBATCH --output=mpi_test_output_%j.log # Standard output file#SBATCH --error=mpi_test_output_%j.err # Standard error file# Manually set Intel OneAPI MPI and Compiler environmentexportI_MPI_PMI=pmi2
exportI_MPI_PMI_LIBRARY=/usr/lib/x86_64-linux-gnu/slurm/mpi_pmi2.so
exportI_MPI_ROOT=/opt/intel/oneapi/mpi/2021.14
exportINTEL_COMPILER_ROOT=/opt/intel/oneapi/compiler/2025.0
exportPATH=$I_MPI_ROOT/bin:$INTEL_COMPILER_ROOT/bin:$PATHexportLD_LIBRARY_PATH=$I_MPI_ROOT/lib:$INTEL_COMPILER_ROOT/lib:$LD_LIBRARY_PATHexportMANPATH=$I_MPI_ROOT/man:$INTEL_COMPILER_ROOT/man:$MANPATH# Compile the MPI programicx-cc -I$I_MPI_ROOT/include hello_mpi.c -o hello_mpi -L$I_MPI_ROOT/lib -lmpi
# Run the MPI jobmpirun -np 2 ./hello_mpi
#!/bin/bash
#SBATCH --job-name=mpi_job # Job name#SBATCH --nodes=2 # Number of nodes to use#SBATCH --ntasks-per-node=1 # Number of tasks per node#SBATCH --time=00:10:00 # Time limit#SBATCH --output=mpi_test_output_%j.log # Standard output file#SBATCH --error=mpi_test_output_%j.err # Standard error file# Manually set Intel OneAPI MPI and Compiler environmentexportI_MPI_PMI=pmi2
exportI_MPI_PMI_LIBRARY=/usr/lib/x86_64-linux-gnu/slurm/mpi_pmi2.so
exportI_MPI_ROOT=/opt/intel/oneapi/mpi/2021.14
exportINTEL_COMPILER_ROOT=/opt/intel/oneapi/compiler/2025.0
exportPATH=$I_MPI_ROOT/bin:$INTEL_COMPILER_ROOT/bin:$PATHexportLD_LIBRARY_PATH=$I_MPI_ROOT/lib:$INTEL_COMPILER_ROOT/lib:$LD_LIBRARY_PATHexportMANPATH=$I_MPI_ROOT/man:$INTEL_COMPILER_ROOT/man:$MANPATH# Compile the MPI programicx-cc -I$I_MPI_ROOT/include dot_product.c -o dot_product -L$I_MPI_ROOT/lib -lmpi
# Run the MPI jobmpirun -np 2 ./dot_product
#include<stdio.h>#include<mpi.h>intmain(intargc,char*argv[]){intrank,size;// 初始化MPI环境
MPI_Init(&argc,&argv);// 获取当前进程的rank和总进程数
MPI_Comm_rank(MPI_COMM_WORLD,&rank);MPI_Comm_size(MPI_COMM_WORLD,&size);// 输出进程的信息
printf("Hello, World! I am process %d out of %d processes.\n",rank,size);// 退出MPI环境
MPI_Finalize();return0;}
#include<stdio.h>#include<stdlib.h>#include<mpi.h>#define N 8 // 向量大小
// 计算向量的局部点积
doublecompute_local_dot_product(double*A,double*B,intstart,intend){doublelocal_dot=0.0;for(inti=start;i<end;i++){local_dot+=A[i]*B[i];}returnlocal_dot;}voidprint_vector(double*Vector){for(inti=0;i<N;i++){printf("%f ",Vector[i]);}printf("\n");}intmain(intargc,char*argv[]){intrank,size;// 初始化MPI环境
MPI_Init(&argc,&argv);MPI_Comm_rank(MPI_COMM_WORLD,&rank);MPI_Comm_size(MPI_COMM_WORLD,&size);// 向量A和B
doubleA[N],B[N];// 进程0初始化向量A和B
if(rank==0){for(inti=0;i<N;i++){A[i]=i+1;// 示例数据
B[i]=(i+1)*2;// 示例数据
}}// 广播向量A和B到所有进程
MPI_Bcast(A,N,MPI_DOUBLE,0,MPI_COMM_WORLD);MPI_Bcast(B,N,MPI_DOUBLE,0,MPI_COMM_WORLD);// 每个进程计算自己负责的部分
intlocal_n=N/size;// 每个进程处理的元素个数
intstart=rank*local_n;intend=(rank+1)*local_n;// 如果是最后一个进程,确保处理所有剩余的元素(处理N % size)
if(rank==size-1){end=N;}doublelocal_dot_product=compute_local_dot_product(A,B,start,end);// 使用MPI_Reduce将所有进程的局部点积结果汇总到进程0
doubleglobal_dot_product=0.0;MPI_Reduce(&local_dot_product,&global_dot_product,1,MPI_DOUBLE,MPI_SUM,0,MPI_COMM_WORLD);// 进程0输出最终结果
if(rank==0){printf("Vector A is\n");print_vector(A);printf("Vector B is\n");print_vector(B);printf("Dot Product of A and B: %f\n",global_dot_product);}// 结束MPI环境
MPI_Finalize();return0;}